A few goodies I’d ordered all arrived nearly at once on Saturday, and I thought I’d share them here.
Business card
New business cards! Tap to view at full size.
It’s been a while since I’ve had an honest-to-goodness business card, but since NetFoundry makes them available to employees and since a good chunk of my job is about making myself available to the public, I placed an order and received two boxes containing a few hundred cards in total.
These days, I tend to simply display my LinkedIn QR code on my phone when exchanging contact details with people, but I still like the old-school feel of giving someone a card (which just so happens to contain my LinkedIn QR code).
I know a couple of the authors. Way back in 2016, Ted reached out to me after I’d landed a developer relations job with SMARTRAC and wanted to see how they did developer relations. I also know David from my time at Auth0, because shortly after I joined, Auth0 merged with Okta, where David worked. In fact, to prepare for my technical interview with Auth0, my primary resource was David’s 2019 article in the Okta Developer blog, An Illustrated Guide to OAuth and OpenID Connect.
Since I’m now pretty much Supreme Developer Advocate at NetFoundry (I’m the only one; it’s a small, scrappy company that punches above its weight class), I figured the book would be useful.
Also, I have a policy of buying books written by people I know, as illustrated in the meme below:
I try to be cash money all the time. Tap to view at full size.
You may have noticed that I bought the dead-tree edition instead of an electronic one. This also follows a rule of mine:
If the content is ephemeral or likely to be outdated in a couple of years (or a couple of months, given the pace of change these days), get the electronic version.
If the content is likely to be longer-lasting or seems timeless, get the paper version.
Also, it’s nice to get away from screens from time to time. I’ve carved out a little time each day to sit on the rocking chair on our front porch and read paper books, and Developer Relations Activity Patterns will be one of them.
Teeny-weeny hard drive
Nice and compact! Tap to view at full size.
Between the RAMpocalypse brought about by AI data centers hogging all the storage chips and the war in Iran blocking off access to a large chunk of the world’s helium (it’s a key part of making high-end chips; see my earlier article for an explanation), SSD prices are climbing.
Fortunately, there was a very short-time deal for a two-pack of 2TB Lexar SL500 SSDs for about $400, so we placed an order so that Anitra and I could each have one. They arrived on Saturday, and they’re about the size of my business card!
Meet “Slopportunity,” my new M5 MacBook Pro, purchased with the assistance of the home office stipend that my new employer, NetFoundry, provides. It has lots of RAM and drive space for running and storing models, and it runs circles around my old M1 machine. But I can’t help being reminded of Angelina Jolie’s line from Hackers: “It’s too much machine for you.”
Hopefully, that won’t turn out to be true.
Here’s Slopportunity on the Primary Processor Perch in my home office:
And what of my old laptop, an M1 MacBook Pro with still-decent specs? I’m hanging onto it, I’ve rechristened it as “Sloperator,” and will be my OpenClaw/long-running agents machine:
When the M1 was my main computer, my prior computer, an Intel-based PowerBook, was doing yeoman service. It will live forever, as it’s going to my mother-in-law, who needs a better computer than her old 2009 laptop for browsing, email, and so on:
The world just changed, and retail hasn’t caught up yet
I’ve been watching the news out of the Middle East with the same mix of alarm and exhaustion as everyone else. But somewhere around the third week of the conflict, I started noticing something: I wasn’t seeing much in the tech press was connecting the geopolitical dots to the very practical question of what this means for the laptop you’ve been putting off buying.
So let me do that.
What’s happening right now is not some distant economic abstraction. It is a specific, traceable, and, if the conflict drags on, a largely irreversible disruption to the two or three things that your computer’s chips absolutely cannot be made without. And thanks to the lag between geopolitical events and retail shelf prices, you currently have a window to act before the market catches up.
TL;DR for the short attention span reader
The situation: The U.S./Israel war on Iran has closed the Strait of Hormuz, and that single choke point controls a staggering amount of the supply chain that makes your computer’s chips, RAM, and storage.
The two affected countries that will affect hardware:
Qatar, which produces about one-third of the world’s helium, has had its main natural gas and helium facility bombed and its exports blocked. Helium is irreplaceable in semiconductor manufacturing, and there’s no substitute.
South Korea (home to Samsung and SK Hynix, who together make most of the world’s DRAM and NAND flash) imports roughly two-thirds of its helium from Qatar and is heavily dependent on Middle Eastern oil for the energy that runs those fabs. Both inputs are now severely disrupted.
The thing you need to know: RAM and SSD prices were already in crisis before the war started, driven by AI data centers consuming chips faster than manufacturers can make them. The war just poured gasoline on a fire that was already burning.
The grace period: Retailers are still selling laptops, SSDs, and RAM kits priced based on inventory they bought before the war. That lag is roughly 3 to 6 weeks. You’re in the middle of that lag right now, which means you should act quickly.
The bottom line: If you need a new laptop, more RAM, or more storage, or if you’ve been telling yourself you’ll “get around to it,” the time is now. Prices are going up. The only real question is by how much.
The long version
First, some context: The war
On February 28, 2026, the United States and Israel launched Operation Epic Fury, which was a set of coordinated (and based on the news reports, I’m using the term “coordinated” somewhat loosely here) strikes on Iranian military infrastructure and leadership.
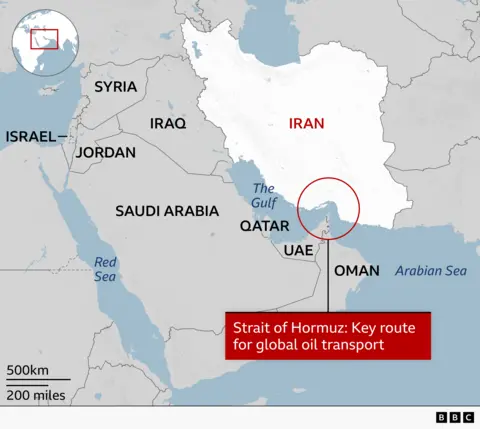
Iran retaliated by closing the Strait of Hormuz, the narrow waterway through which approximately 20% of the world’s seaborne oil passes every day. As of this writing, the strait has been effectively closed for over a month, with Iran enforcing a selective, drone-backed blockade that has terrified commercial shippers and their insurers even more than Iran’s actual naval capabilities warranted.
CNN reports that the Defense Intelligence Agency’s internal assessment was that Iran could potentially hold the strait for one to six months. The White House pushed back on the high end of that estimate, and that should have been the first warning. The strait has already been closed for five weeks.
None of this is theoretical anymore. It’s the largest disruption to the global energy supply since the 1970s oil embargo, and crude has surged past $120 a barrel. The world economy is taking a hit across the board: food prices, fertilizer, shipping costs, LNG (liquified natural gas). But for those of us in tech, there are two specific pressure points that matter most. Let me take them one at a time.
Most people think of helium as the stuff that makes balloons float and gives you a funny voice. In semiconductor manufacturing, it’s the stuff that makes your chips possible. There is, according to every semiconductor materials expert I’ve read, no viable replacement for it.
Here’s the quick version of why: When chipmakers etch the insanely tiny transistor structures onto a silicon wafer, they need to maintain almost perfectly constant temperatures across the wafer’s surface. Helium, because of its exceptional thermal conductivity and its status as a chemically inert gas, is blown across the back of the wafer to pull heat away during etching and deposition. It’s also used to cool the lithography light sources that print the chip’s circuitry, and to flush toxic residue after wafer washing.
You can’t swap helium out. You can’t use argon. Nitrogen is also a no-go. You use helium, or you don’t make chips.
Isn’t helium supposed to be the second-most common element in the universe?
The irony about helium is practically and literally on a cosmic level. Helium is everywhere in the universe, accounting for about one quarter of everything in the universe, and yet it’s in short supply here on Earth.
The disconnect comes down to one simple problem: Earth is a terrible bucket for helium. It just won’t stay put here.
Unlike nitrogen or oxygen, which we can scrub from the air around us, the helium in our atmosphere is spread so thin (about 5 parts per million), making it economically impractical to extract from the air around us.
Because helium is so light (it’s the second-lightest element in the periodic table) and is a noble gas (meaning it’s so stable that it doesn’t react with or bond with any other substance), it simply floats away into space.
So where does helium come from?
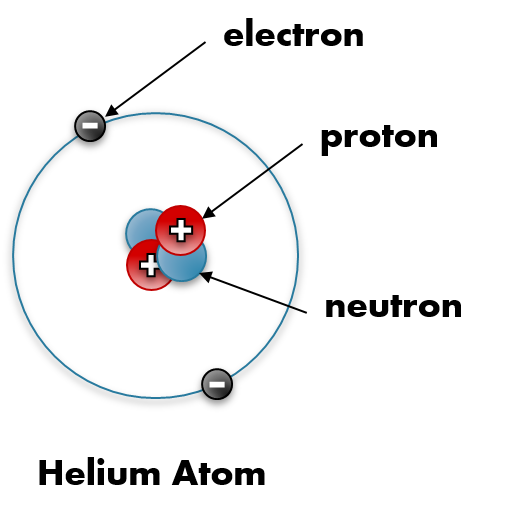
Almost all the helium we use on Earth is a byproduct of radioactive decay. Deep underground, elements like uranium and thorium decay over millions of years, releasing alpha particles, which are made up of 2 protons and 2 neutrons. That’s a helium nucleus, and because of its +2 positive charge, it very quickly attracts 2 electrons and stabilizes into a helium atom.
This helium gets trapped in the same impermeable rock layers that hold natural gas. When we drill for gas, we occasionally strike a “helium-rich” pocket. If we don’t capture it then, it’s gone.
The United States is the world’s largest helium producer. But the second largest, according to the U.S. Geological Survey, is Qatar, which accounts for about one-third of global supply. Russia is another major source, but Russian helium is currently under U.S. and EU sanctions (at least at the time of writing). Algeria produces some as well, but not nearly enough to fill the gap.
Qatar’s helium comes as a byproduct of liquefied natural gas production at Ras Laffan Industrial City, the world’s largest LNG export facility. On March 2, Iran attacked Ras Laffan with drones. Later in the month, Iranian missiles hit it again.
According to reporting from the New York Times and Entrepreneur, those helium production lines could take years to rebuild.
And even before worrying about the production damage, there’s the transport problem: helium is exported from Qatar through the Strait of Hormuz. Which is closed.
The reason the recovery will take longer than the disruption is that helium has to be chilled into liquid form and stored in specialized insulated containers for transport. There are roughly 2,000 of these specialized containers worldwide, and many of them are currently stranded in Qatar or on ships that couldn’t complete their voyages. Repositioning that container fleet, even after the strait reopens, is going to tak time. Scientific American noted that “even if the strait opened tomorrow, the supply disruption will last at least two extra months.”
Spot prices for helium have already risen 70–100% over pre-war levels. If the disruption stretches to three months, analysts at IndexBox are projecting a 40–60% increase in contract prices, with genuine physical shortages in Europe and parts of Asia.
Who Gets the Helium That’s Left?
Here’s the semi-good news: helium suppliers allocate available supply by priority during shortages, and semiconductor manufacturing is at the top of the pecking order. Party balloons are at the bottom (sorry, kids). Medical MRI machines and chip fabs will be the last to lose access.
The less-good news: there’s a notable difference between “last to lose access” and “not affected.” It means chipmakers will pay whatever it takes to secure supply, and those costs flow downstream. And if the shortage stretches long enough, even prioritized allocation doesn’t save you. You’re just out of luck… and out of helium.
Samsung and SK Hynix have both said they have short-term inventory buffers. The Korea Semiconductor Industry Association says short-term supplies are sufficient. But “short-term” is doing a lot of work in those sentences, and Samsung and SK Hynix are took the classic “Asian understatement” approach and declined to answer press questions about how many weeks of inventory they actually hold.
Pressure point #2: South Korea is in a very bad position
Samsung and SK Hynix together produce the vast majority of the world’s DRAM (the RAM in your laptop, desktop, and phone) and NAND flash (the storage in your SSD, a.k.a. “hard drive”). Both companies are based in South Korea. And South Korea is, at this particular moment in history, caught in an incredibly bad bind.
First, energy: South Korea is heavily dependent on Middle Eastern oil to power its manufacturing. Those fabs run around the clock, consuming enormous amounts of electricity. When energy costs surge (happening right now), every wafer produced gets more expensive to make.
Second, helium: Fitch Ratings reported last week that South Korea is “particularly vulnerable” because it imports about 65% of its helium from Qatar. That supply is now offline, and South Korea’s Ministry of Trade, Industry and Resources has opened an emergency review of 14 semiconductor supply chain materials with high Middle Eastern dependence.
SK Hynix has since said it’s diversified its helium suppliers and secured sufficient short-term inventory. Samsung has said nothing publicly. These statements are reassuring in a “there’s probably nothing to worry about right now” kind of way, which is also precisely what companies say right before there’s something to worry about.
Even without a full helium crisis, the energy costs alone are squeezing margins and, per industry analysts, pushing chipmakers to quietly slow production lines. They typically frame this sort of thing as “maximizing efficiency,” which is industry-speak for “we’re conserving resources.”
The fire was already burning before the war started
Here’s the piece of context that most of the war-focused tech coverage has skipped over, but that you absolutely need to understand: RAM and SSD prices were already in a serious crisis before February 28th.
This is not a new fire. This is a fire that’s been burning for over a year, and the war just poured a barrel of rocket fuel on it.
The root cause (surprise, surprise) is AI. Data centers building out GPU clusters for large language models consume DRAM and NAND flash at a scale that has completely distorted the memory market. Samsung, SK Hynix, and Micron have all been redirecting manufacturing capacity toward high-bandwidth memory (HBM), the specialized RAM that feeds Nvidia’s H100s and B200s, and away from conventional DDR5 and consumer NAND. Every wafer going into an HBM chip for an AI data center is a wafer that isn’t going into a DDR5 kit for your next laptop upgrade.
The consequences have been dramatic:
TrendForce reported in January that conventional DRAM contract prices were forecast to rise 55–60% quarter-over-quarter in Q1 2026. NAND flash was projected to rise 33–38%. (You can see their trend report on current DRAM prices here.)
Gartner published a forecast on February 26, two days before the war started, projecting a 130% combined surge in DRAM and SSD prices by end of 2026, driving PC prices up 17% year-over-year.
Micron has already exited the consumer memory business entirely, abandoning its Crucial brand to focus exclusively on AI data center customers. That leaves Samsung and SK Hynix as the only two major DRAM manufacturers still serving the consumer and developer market.
Tom’s Hardware has been tracking 32GB DDR4 kits that cost $60–90 in October 2025 now selling for $150–180. DDR5 32GB kits that were sub-$200 are now pushing $350+, and the cheapest are selling out.
The war doesn’t create this problem. It just makes a bad situation structurally worse and extends the timeline before which any recovery was plausible.
The grace period, and why it’s closing
Here is the most important practical fact in this entire article: retailers are currently selling hardware that they bought at pre-war prices.
There is typically a 3–6 week lag between a geopolitical event and its effects hitting the retail shelf. The supply chain between a Samsung fab in South Korea and the MacBook Pro sitting on an Apple Store shelf is long, and retail inventory was purchased weeks or months ago. Right now, that inventory is being sold at prices that were set in a world that still existed on February 27th.
That window is closing. Wholesale prices from distributors are already moving. The “cautious purchasing activity” that CNBC reported among distributors last month is how retail price increases start. Retailers who need to reorder will pay more. They will pass that along.
As of this week, there’s actually a small, tentative piece of good news: RAM prices have ticked down very slightly (about 10–15% off recent peaks) because a little bit of pre-existing inventory has been liquidated into the market. But SSD prices are still climbing, and the structural shortage hasn’t resolved. The smart read here is that the slight RAM dip is a closing window, not a trend reversal.
Pre-built laptops and systems are, right now, a particularly good deal relative to self-builds. That’s almost never true. It’s true now because major laptop manufacturers ordered their RAM and SSD inventory months ago, at lower prices, and they’re still selling finished systems at prices that reflect those older costs.
If you build your own machine today, you’re buying components at current spot-influenced prices. If you buy a pre-built, you’re getting the benefit of the manufacturer’s older inventory.
What developers and techies should actually buy, and when
If you’re a developer or someone whose work depends on a capable machine, here’s how I’d think about this:
Laptops: Buy now. This is the strongest “act immediately” category. Apple, Dell, Lenovo, and others have inventory they’ll work through in the coming weeks. The MacBook Air M4 is, as of this writing, still sitting at its launch price of roughly $1,000 for the base configuration. Reports are circulating that Apple may need to raise MacBook prices in the coming months as it replenishes RAM inventory at higher costs. The M4 Pro and M4 Max MacBook Pros are similar stories. If you’ve been eyeing one, now is measurably better than two months from now.
Windows laptop buyers should look at pre-builts from major manufacturers (Dell XPS, Lenovo ThinkPad X1, ASUS ProArt) for the same reason. You’re getting the benefit of their old inventory pricing.
RAM upgrades: Also buy now, with some nuance. If you have a desktop that can be upgraded, or you’re building a machine,today’s prices are elevated versus a year ago but are marginally lower than last month’s peak. More importantly, the trajectory from here is up. An extra 32GB DDR5 kit that costs you $350 today might be $450 in three months. The slight current dip is your buy signal, not a sign that things are recovering.
SSDs: Buy now, no nuance. SSD prices are still moving up. The 1TB Samsung 990 Pro is sitting at around $200 on Amazon right now. The same drive was $60 in mid-2023. There’s no sign of relief in the near term. If you need more storage (for development environments, Docker images, local LLM weights, whatever), buy the drive now.
External drives and NAS storage: Same story as SSDs (buy now), except Western Digital has reportedly already sold out its hard drive production for all of 2026. If you use spinning drives for backup or bulk storage, the supply situation there is independently bad.
The wild cards
I’d be giving you an incomplete picture if I didn’t acknowledge the things that could make this better or worse.
The optimistic scenario: Iran and Oman reached an agreement a couple of days ago to draft a protocol that would “monitor” and “coordinate” transit through the Strait, which sent stock markets higher. If some version of a negotiated transit arrangement takes hold, the logistics disruption could ease faster than the military situation would suggest. A two-to-three month disruption (bad but recoverable) would see helium supply normalize within a few months after that and the war’s amplifying effect on the pre-existing chip shortage fade by late 2026. Prices would still be elevated, but not catastrophically.
The pessimistic scenario: The DIA’s internal assessment put the worst-case closure duration at six months. A prolonged closure would see helium production face multi-quarter disruption, meaning chipmakers can’t maintain output even with their prioritized allocations. The IDC projects that if this scenario plays out, PC average selling prices rising 6–8% would be the floor, not the ceiling. The sub-$500 PC effectively disappears. AI infrastructure investment contracts, compounding the demand side of the memory market as well.
Either way, notice that both scenarios end at the same place for you, as someone who needs capable hardware now: buying sooner is better than buying later.
The bottom line: buy now
The world’s chip supply chain runs on helium from Qatar, energy from the Middle East, and manufacturing from South Korea. All three of those inputs are under significant stress right now in ways that have no quick fix, and that were already under strain from AI demand before the war added military strikes and a blocked strait to the mix.
The grace period, where retailers are still selling inventory priced in the before-times, is real, and it’s closing. This isn’t hype or manufactured urgency. The price signals are already moving at the wholesale level.
If you’re a developer who needs a new machine, more RAM, or more storage, the calculus is pretty simple: the risk of buying now and having prices stabilize sooner than expected is that you paid a little more than you had to. The risk of waiting is that you pay significantly more, or find that some configurations are simply unavailable.
While doing Christmas shopping, I stumbled across the device pictured above — the Revolution InstaGLO R180 Connect Plus toaster, which retails for $400 — and thought: Do they not remember the “toaster programmer” joke from the 1990s?
In case you’re not familiar with the joke, it’s one that made the rounds on internet forums back then, as a sort of “text meme.” Here it is…
Once upon a time, in a kingdom not far from here, a king summoned two of his advisors for a test. He showed them both a shiny metal box with two slots in the top, a control knob, and a lever. “What do you think this is?”
One advisor, an Electrical Engineer, answered first. “It is a
toaster,” he said.
The king asked, “How would you design an embedded
computer for it?”
The advisor: “Using a four-bit microcontroller, I would write a simple program that reads the darkness knob and
quantifies its position to one of 16 shades of darkness, from snow white to coal black. The program would use that darkness level as the index to a 16-element table of initial timer values. Then it would turn on the heating elements and start the timer with the initial value selected from the table. At the end of the time delay, it would turn off the heat and pop up the toast. Come back next week, and I’ll show you a working prototype.”
The second advisor, a software developer, immediately recognized the danger of such short-sighted thinking. He said, “Toasters don’t just turn bread into toast, they are also used to warm frozen waffles. What you see before you is really a breakfast food cooker. As the subjects of your kingdom become more sophisticated, they will demand more capabilities. They will need a breakfast food cooker that can also cook sausage, fry bacon, and make scrambled eggs. A toaster that only makes toast will soon be obsolete. If we don’t look to the future, we will have to completely redesign the toaster in just a few years.”
“With this in mind, we can formulate a more intelligent solution to the problem. First, create a class of breakfast foods. Specialize this class into subclasses: grains, pork, and poultry. The specialization process should be repeated with grains divided into toast, muffins, pancakes, and waffles; pork divided into sausage, links, and bacon; and poultry divided into scrambled eggs, hard- boiled eggs, poached eggs, fried eggs, and various omelette classes.”
“The ham and cheese omelette class is worth special attention because it must inherit characteristics from the pork, dairy, and poultry classes. Thus, we see that the problem cannot be properly solved without multiple inheritance. At run time, the program must create
the proper object and send a message to the object that says, ‘Cook yourself.’ The semantics of this message depend, of course, on the kind of object, so they have a different meaning to a piece of toast than to scrambled eggs.”
“Reviewing the process so far, we see that the analysis phase has revealed that the primary requirement is to cook any kind of breakfast food. In the design phase, we have discovered some derived requirements. Specifically, we need an object-oriented language with multiple inheritance. Of course, users don’t want the eggs to get
cold while the bacon is frying, so concurrent processing is
required, too.”
“We must not forget the user interface. The lever that lowers the food lacks versatility, and the darkness knob is confusing. Users won’t buy the product unless it has a user-friendly, graphical interface. When the breakfast cooker is plugged in, users should see a cowboy boot on the screen. Users click on it, and the message ‘Booting UNIX v.8.3’ appears on the screen. (UNIX 8.3 should be out by the time the product gets to the market.) Users can pull down a menu and click on the foods they want to cook.”
“Having made the wise decision of specifying the software first in the design phase, all that remains is to pick an adequate hardware platform for the implementation phase. An Intel Pentium with 48MB
of memory, a 1.2GB hard disk, and a SVGA monitor should be sufficient. If you select a multitasking, object oriented language that supports multiple inheritance and has a built-in GUI, writing the program will be a snap.”
The king wisely had the software developer beheaded, and they all lived happily ever after.
Of course, you could expect me to talk about how good the ZGX Nano is; after all, I’m paid to do so — at least until 5 p.m. Eastern today. But what if a notable AI expert also sang its praises?
Sebastian has been experimenting on NVIDIA’s DGX Spark, which has the same specs as the ZGX Nano (as well as a few other similar small desktop computers built around the NVIDIA’s GB10 “superchip”), and he’s published his observations on his blog in a post titled DGX Spark and Mac Mini for Local PyTorch Development. He ran some benchmark AI programs comparing his Mac Mini M4 computer (a fine developer platform, by the bye) and the NVIDIA H100 GPU (and NVIDIA’s A100 GPU when an H100 wasn’t available), pictured below:
Let me begin from the end of Raschka’s article, where he writes his conclusions:
Overall, the DGX Spark seems to be a neat little workstation that can sit quietly next to a Mac Mini. It has a similarly small form factor, but with more GPU memory and of course (and importantly!) CUDA support.
I previously had a Lambda workstation with 4 GTX 1080Ti GPUs in 2018. I needed the machine for my research, but the noise and heat in my office was intolerable, which is why I had to eventually move the machine to a dedicated server room at UW-Madison. After that, I didn’t consider buying another GPU workstation but solely relied on cloud GPUs. (I would perhaps only consider it again if I moved into a house with a big basement and a walled-off spare room.) The DGX Spark, in contrast, is definitely quiet enough for office use. Even under full load it’s barely audible.
It also ships with software that makes remote use seamless and you can connect directly from a Mac without extra peripherals or SSH tunneling. That’s a huge plus for quick experiments throughout the day.
But, of course, it’s not a replacement for A100 or H100 GPUs when it comes to large-scale training.
I see it more as a development and prototyping system, which lets me offload experiments without overheating my Mac. I consider it as an in-between machine that I can use for smaller runs, and testing models in CUDA, before running them on cloud GPUs.
In short: If you don’t expect miracles or full A100/H100-level performance, the DGX Spark is a nice machine for local inference and small-scale fine-tuning at home.
You might as well replace “DGX Spark” in his article with “ZGX Nano” — the hardware specs are the same. The ZGX Nano shines with HP’s exclusive ZGX Toolkit, a Visual Studio Code extension that lets you configure, manage, and deploy to the ZGX Nano. This lets you use your favorite development machine and coding environment to write code, and then use the ZGX Nano as a companion device / on-premises server.
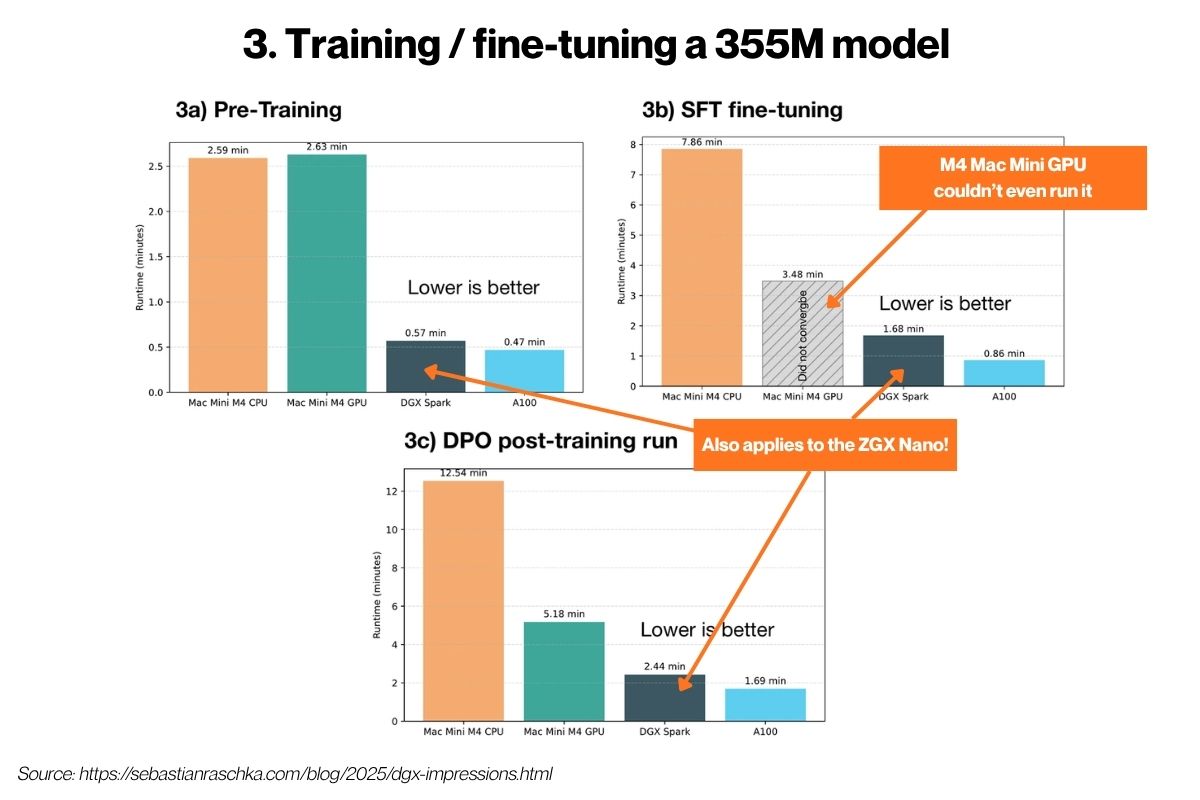
The article features graphs showing his benchmarking results…
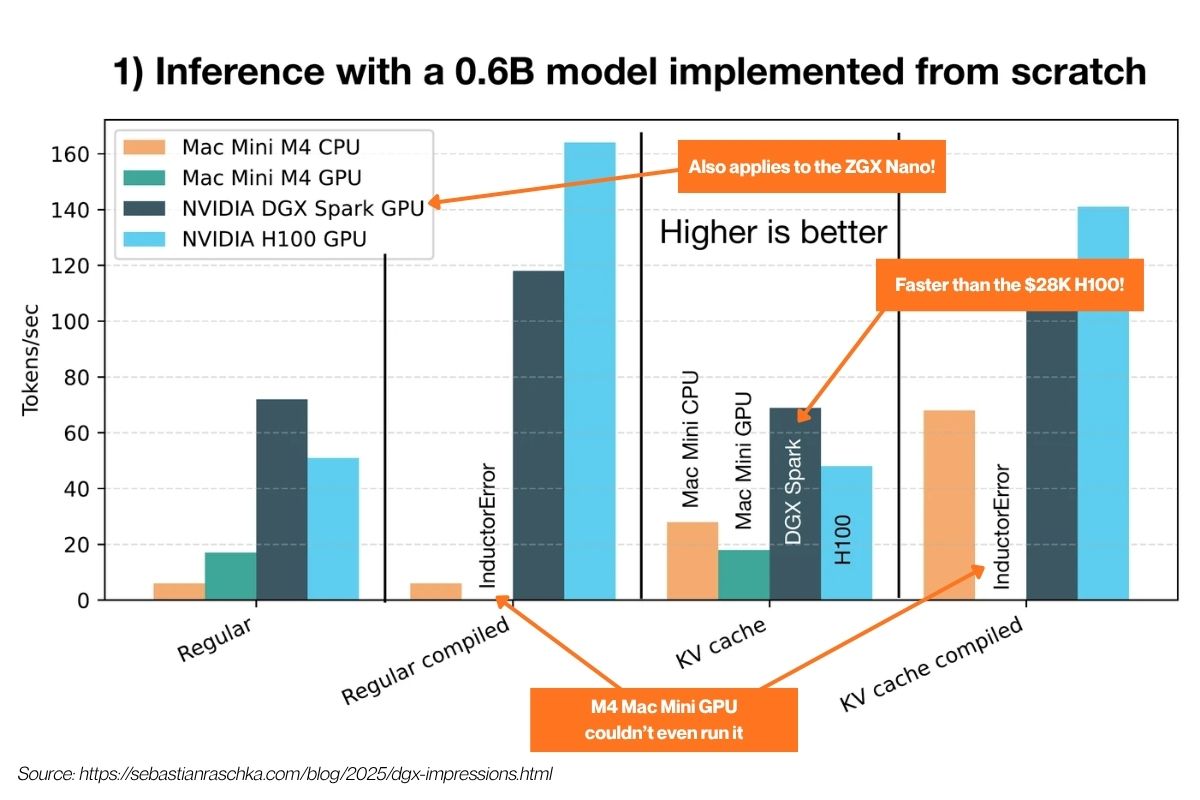
In his first set of benchmarks, he took a home-built 600 million parameter LLM — the kind that you learn how to build in his book, Build a Large Language Model (from Scratch) — and ran it on his Mac Mini M4, the ZGX Nano’s twin cousin, and an H100 from a cloud provider. From his observations, you can conclude that:
With smaller models, the ZGX Nano can match a Mac Mini M4. Both can crunch about 45 tokens per second with 20 billion parameter m0dels.
The ZGX Nano has the advantage of coming with 128GB of VRAM, meaning that it can handle larger models than the MacMini could, as it’s limited by memory.
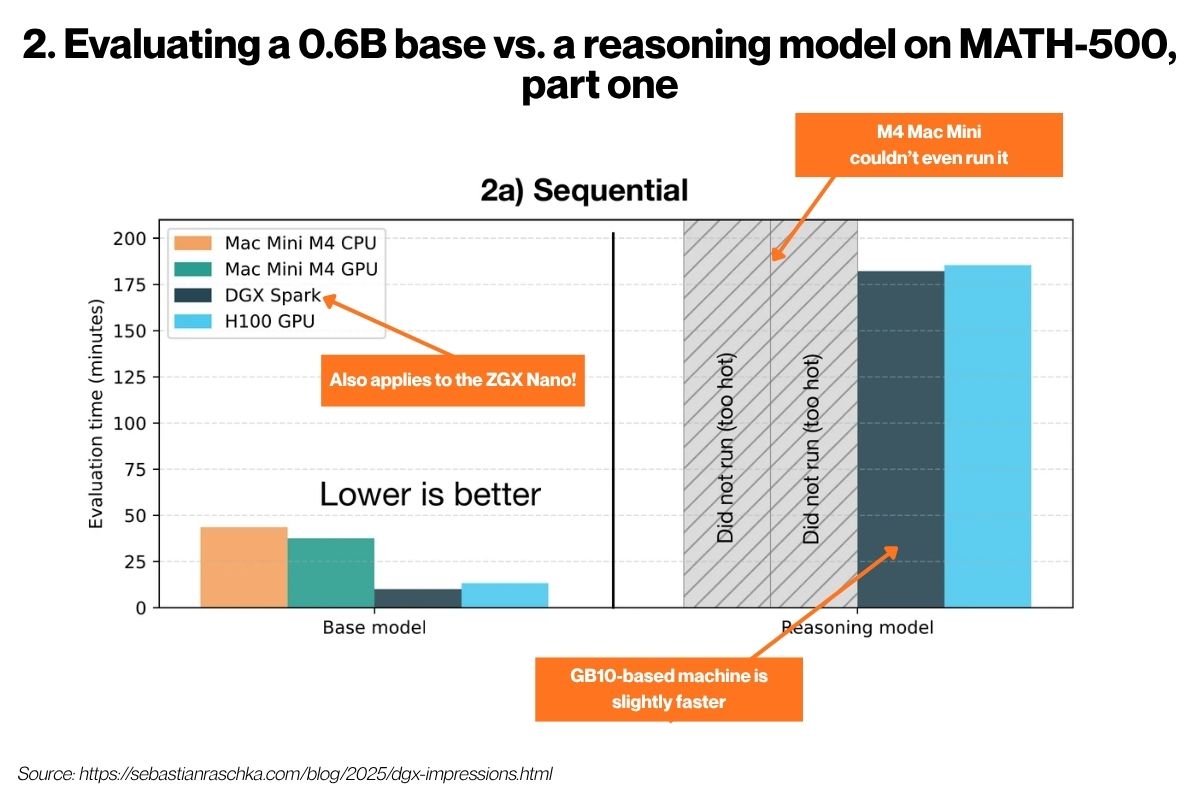
Raschka’s second set of benchmarks tested how the Mac Mini, the ZGX Nano’s twin cousin, and the H100 handle two variants of a model that have been presented with MATH-500, a collection of 500 mathematical word problems:
The base variant, which was a standard LLM that gives short, direct answers
The reasoning variant, which was a version of the base model that was modified to “think out loud” through problems step-by-step
He ran two versions of this benchmark. The first was the sequential test, where the model was presented on MATH-500 question at a time. From the results, you can expect the ZGX Nano to perform almost as well as the H100, but at a significantly smaller fraction of the cost! It also runs circles around the Mac Mini.
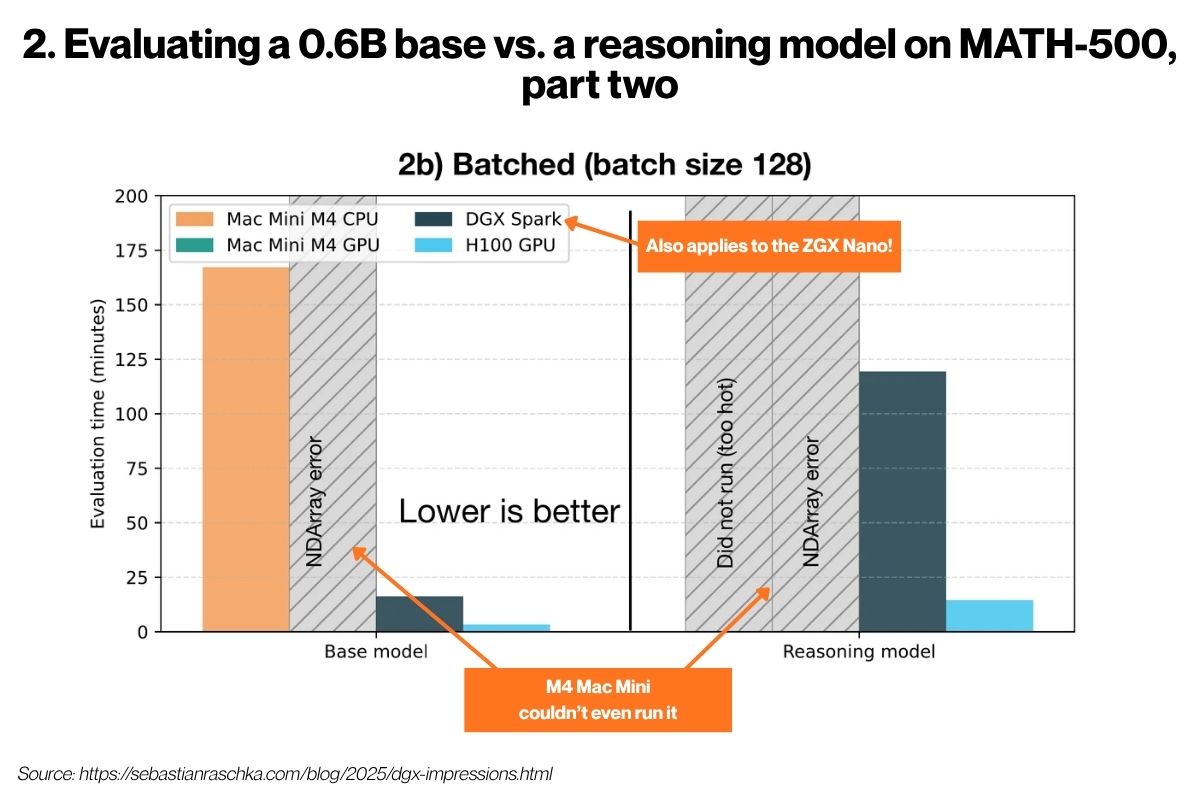
In the second version of the benchmark, the batch test, the model was served 128 questions at the same time, to simulate serving multiple users at once and to. test memory bandwidth and parallel processing.
This is a situation where the H100 would vastly outperform the ZGX Nano thanks to the H100’s much better memory bandwidth. However, the ZGX Nano isn’t for doing inference at production scale; it’s for developers to try out their ideas on a system that’s powerful enough to get a better sense of how they’d operate in the real world, and do so affordably.
Finally, with the third benchmark, Rashcka trained and fine-tuned a model. Note that this time, the data center GPU was the A100 instead of the H100 due to availability.
This benchmark tests training and fine-tuning performance. It compares how fast you can modify and improve an AI model on the Mac Mini M4 vs. the ZGX Nano’s twin vs. an A100 GPU. He presents three scenarios in training and fine-tuning a 355 million parameter model:
Pre-training (3a in the graphs above): Training a model from scratch on raw text
SFT, or Supervised fine-tuning (3b): Teaching an existing model to follow instructions
DPO (direct preference optimization), or preference Tuning (3c): Teaching the model which responses are “better” using preference data
All these benchmarks say what I’ve been saying: the ZGX Nano lets you do real model training locally and economically. You get a lot of bang for your ZGX Nano buck.
As with a lot of development workflows, where there’s a development database and a production database, you don’t need production scale for every experiment. The ZGX Nano gives you a working local training environment that isn’t glacially slow or massively expensive.
The video features the How Computers Work “Under the Hood” presentation that I gave at a Tampa Devs meetup on November 15, 2023.
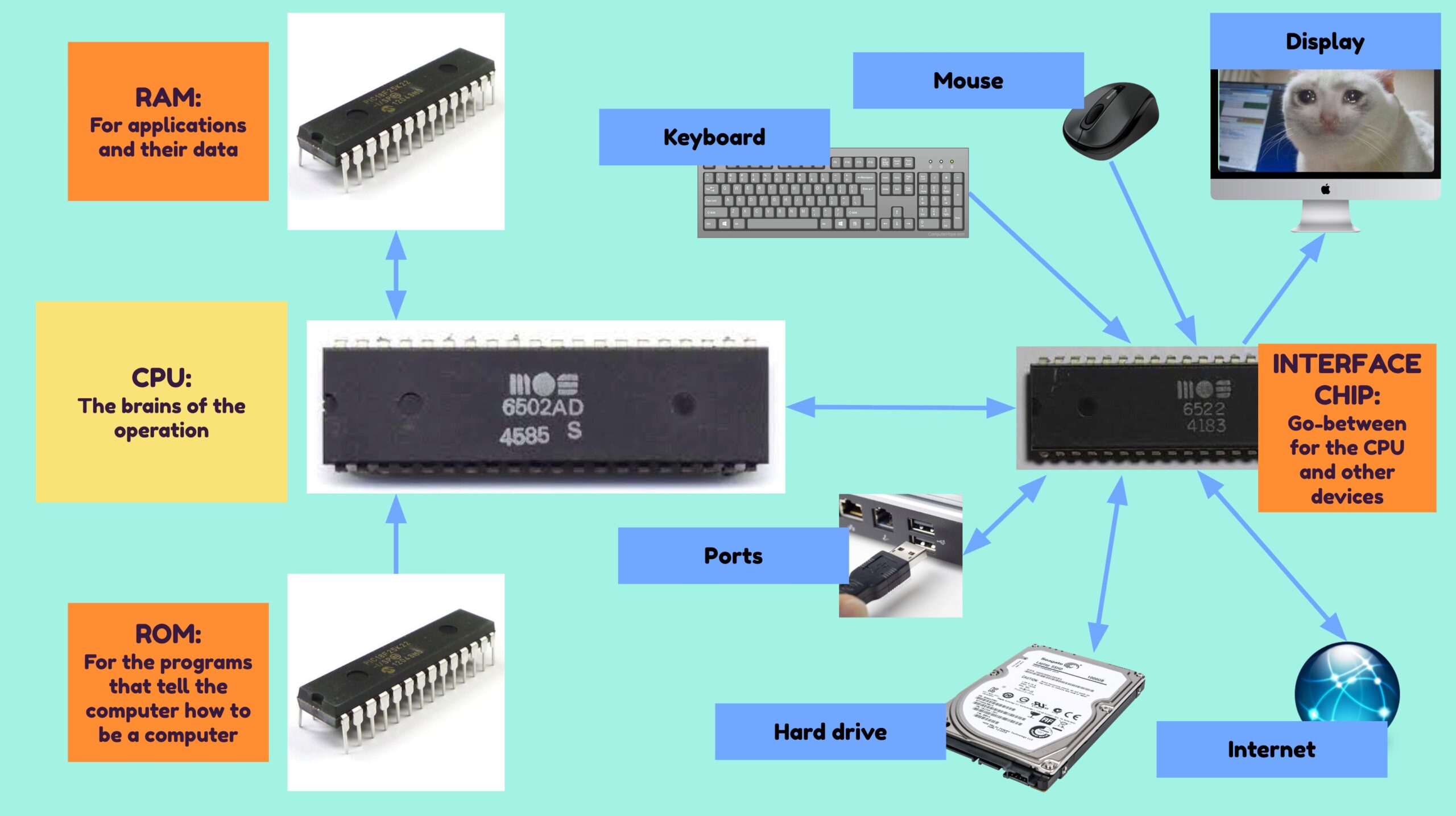
In the presentation, I start by talking about the CPU chips in our computers, phones, and electronic devices:
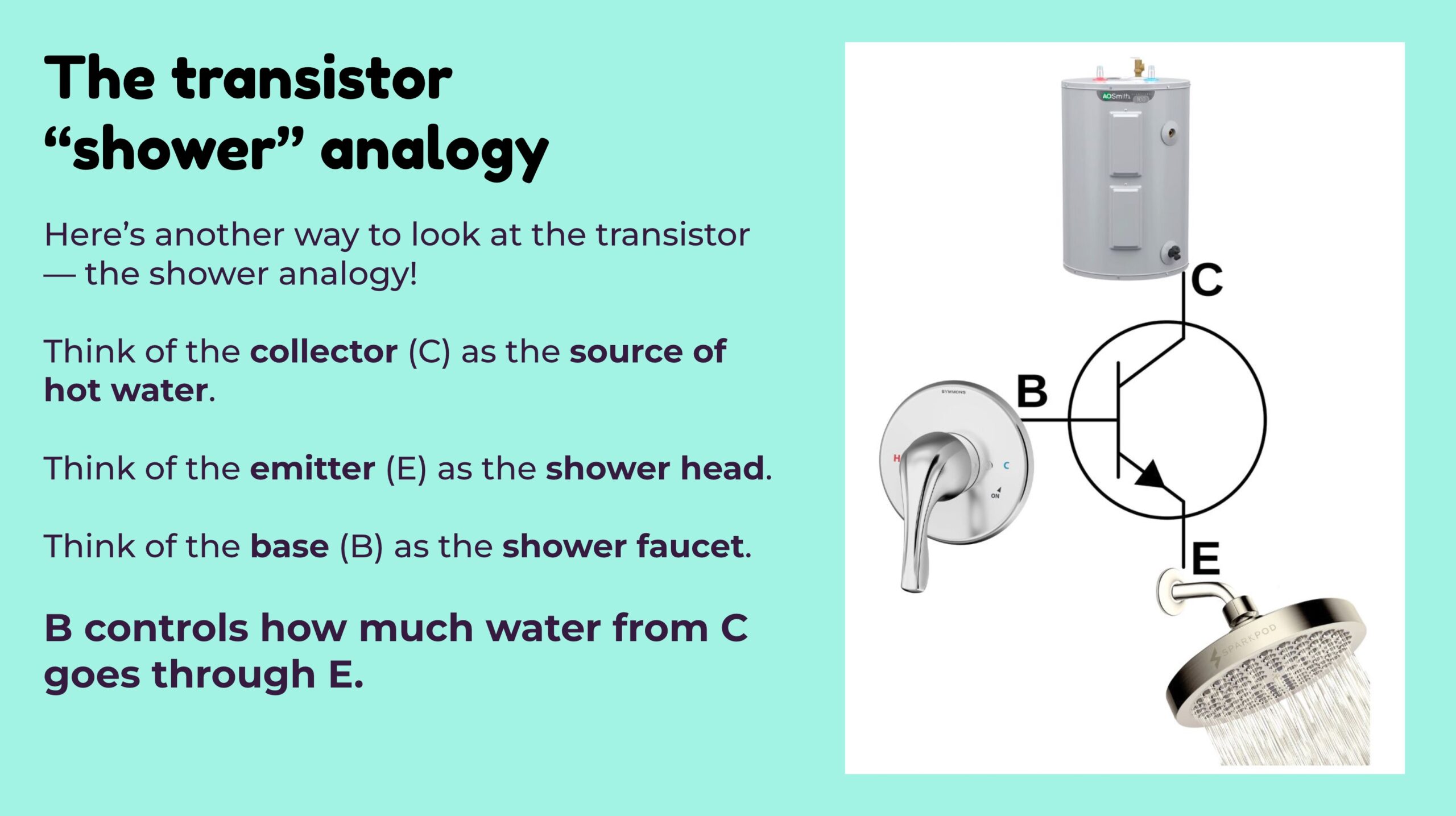
…and then proceed to talk about the building blocks for these chips, transistors:
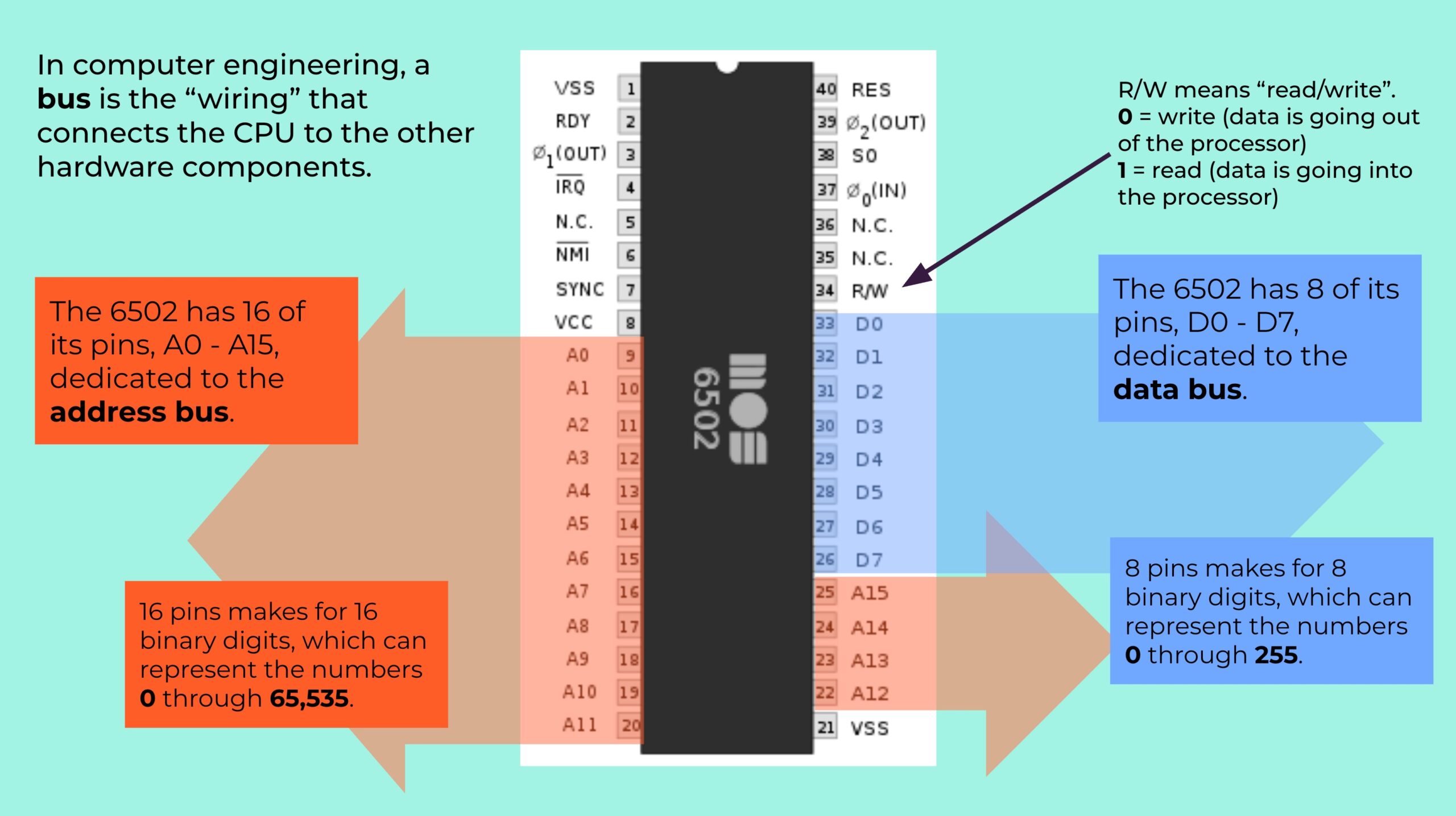
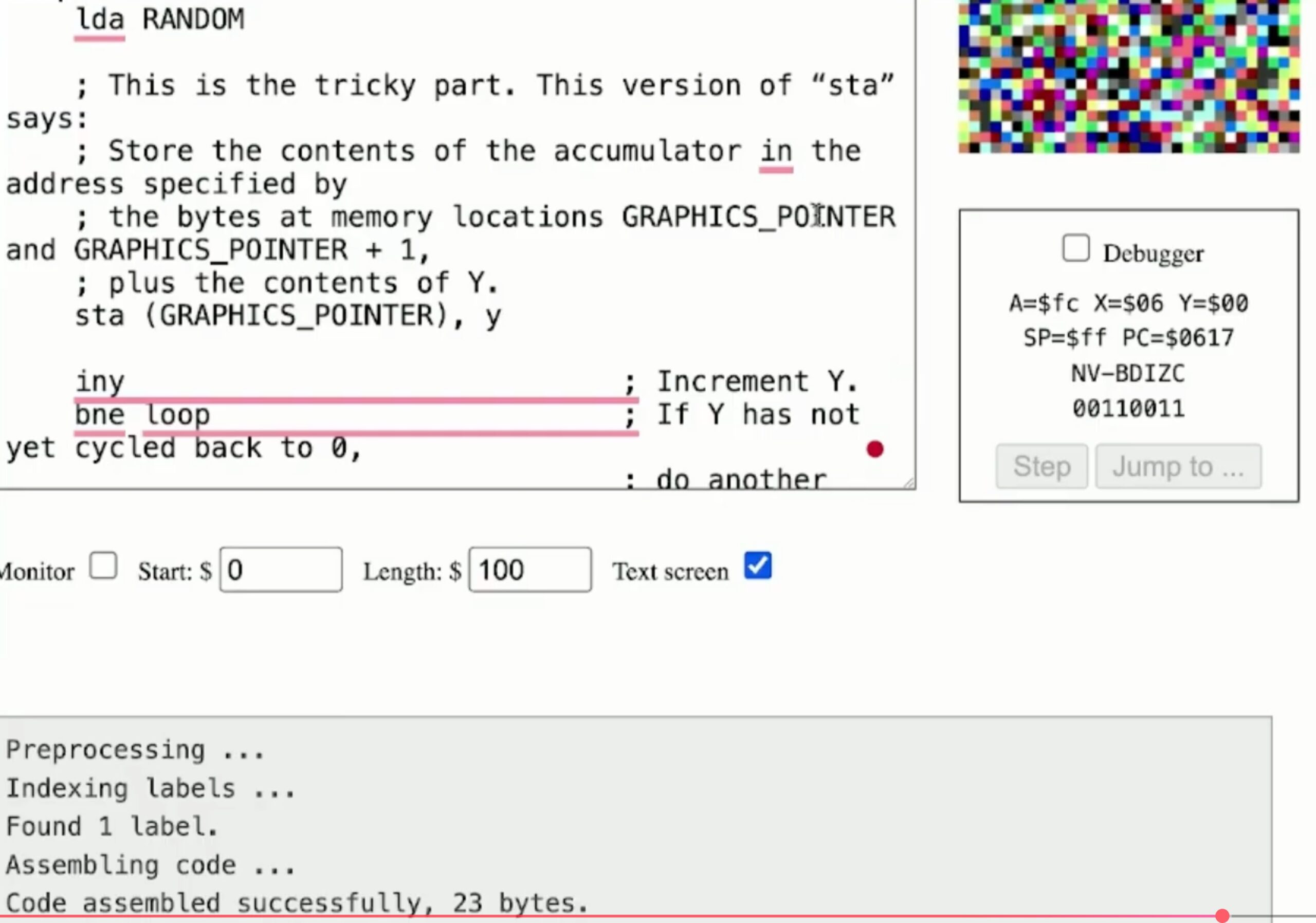
Then, after a quick introduction to the 6502 processor, which powered a lot of 1980s home computers…
…I introduced 6502 assembly language programming:
Watch the video, and learn how your computer works “under the hood!”
If you’d like to follow along with the video try out the exercises I demonstrated, you can do so from the comfort of your own browser — just follow this guide!