This is the first in “Cobra Pi”, a series of articles on getting the most out of your Raspberry Pi!
Yes, you can run Visual Studio Code on Raspberry Pi!
You’ve got many options for editing code or other plain text files on your Raspberry Pi. It is, after all, a Linux machine, and you’ve got all the classic command-line editors — vim, emacs, and…
And the windows-and-mouse-based Geany (text editor) and Thonny (beginner-friendly Python IDE) come along with even the bare-bones version of the Raspberry Pi OS setup.
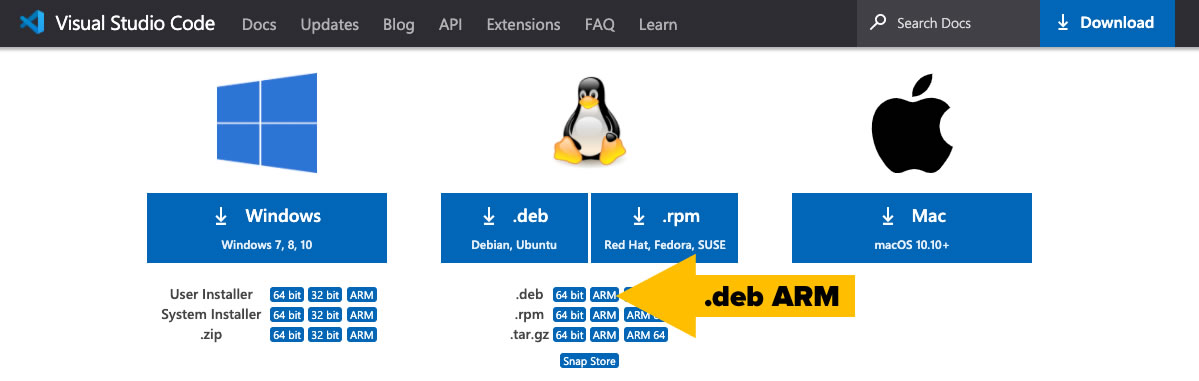
For the Raspberry Pi, you want to download the Debian package for systems with ARM processors (click on the ARM button in the .deb row).
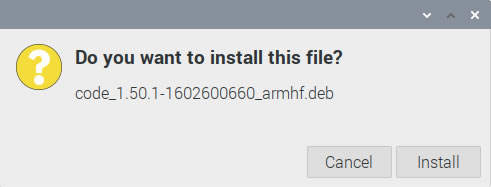
Once downloaded, go to your Downloads directory and double-click on the the .deb file you just downloaded. You’ll see greeted with this dialog box:
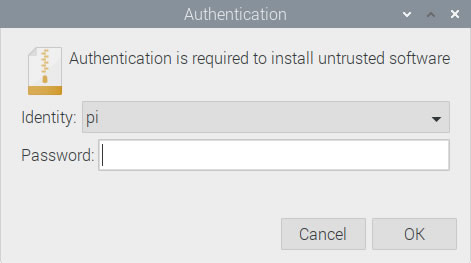
Click the Install button. You’ll be presented with another dialog box, this time asking for your user password, since it’s required when installing new applications:
Enter the password you use to log into the Raspberry Pi into the Password field and click OK.
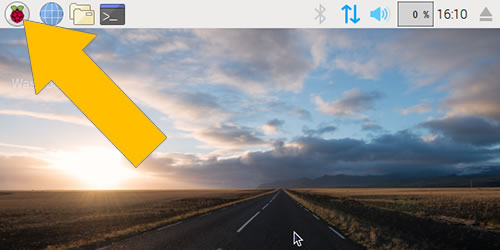
Visual Studio Code will be installed on your Pi. Once the process is done, you can launch it by clicking on the Start Menu (the raspberry icon in the upper left-hand corner)…
…and in the menu that appears, select the Programming menu. A sub-menu will appear, and one of the items will be Visual Studio Code. Click that and…
Tap to view at full size.
You’ll be in the Visual Studio Code that you know and love from Windows, macOS, and Linux! And yes, all the plugins that you’ve come to depend on will be available.
The Raspberry Pi 400 — a Raspberry Pi 4 board with 4GB RAM built into a compact keyboard — was announced just today, and the base unit (just the computer built into the compact keyboard) retails for $70!
The computer
Tap to view at full size.
The Raspberry Pi 400 is a slightly updated model from last year’s Raspberry Pi 4, and has these specs:
Feature
Notes
Processor
1.8 GHz ARM Cortex-A72 CPU
(A little faster than the Raspberry Pi 4’s 1.5 GHz CPU)
RAM
4 GB
Networking
802.11ac wifi
Gigabit Ethernet
Bluetooth 5.0
Video
2 micro HDMI ports that can each drive 4K/60 Hz video
USB
2 USB 3.0 ports
1 USB 2.0 port (preferably for the mouse)
Power
Provided via adapter and USB-C
Additional ports
40-pin GPIO interface
The complete kit
Tap to view at full size.
For an extra $30, you can get the kit, which is the complete “ready to go out of the box” package. It starts with the Raspberry Pi 400 computer-in-a-keyboard unit described above, and it adds:
The kind of computer that hasn’t been seen since the 1980s
Let’s quickly take stock of what you get with just the Raspberry Pi 400, never mind the kit:
A fully-equipped computer with a decent processor, decent RAM, wifi/wired/Bluetooth networking with 2 fast USB ports to spare once you’ve plugged a mouse into the slower one.
A computer that you can do hardware experiments with, thanks to its GPIO pins, and an abundance of hobbyist-focused expansion kits.
A computer that you can plug into your TV.
A computer that costs $100.
There hasn’t been a computer like this since the machines pictured below came out…
…and those machines couldn’t hold a candle to the proper desktops of that era.
On the other hand, you’ll find that the Raspberry Pi 400 can easily keep up with the sort of computer that gets issued for standard office work. You could easily use it to do schoolwork or office work, and it’s actually a decent Linux software development machine and retro-style gaming console, too! And with its expansion capabilities, it’s an excellent machine for IoT and sensor projects.
This is the sort of machine that children of the 1980s and early 1990s learned on, many of whom are today’s techies…
…and this machine will probably be the machine that a lot of children of the 2020s will cut their programming teeth on, and who’ll be the techies of the 2040s and 2050s.
Given a choice between a Chromebook and a Raspberry Pi 400, I’d take the Pi, because I can do a lot more with it. In fact, I might be able to do a lot of my new job with it (which is something I might try soon, just to see what happens).
By the bye, keep an eye on this blog for a new feature: Cobra Pi, which covers programming on the Raspberry Pi, and whose motto is: “Code hard! Fail fast! No latency!”
It’ll cover all sorts of cool programming tips, tricks, and techniques on the Raspberry Pi, including JavaScript, Python, and even C and ARM assembly language!
…go check your drawers. I just opened the drawer on my right-side desk and this is what I saw:
Tap to view at full size.
And these are the ones that aren’t being used to charge phones, iPads, Apple watches, or drive other USB-powered things including my videochat lighting rig.
You probably have lots of them around your place as well.
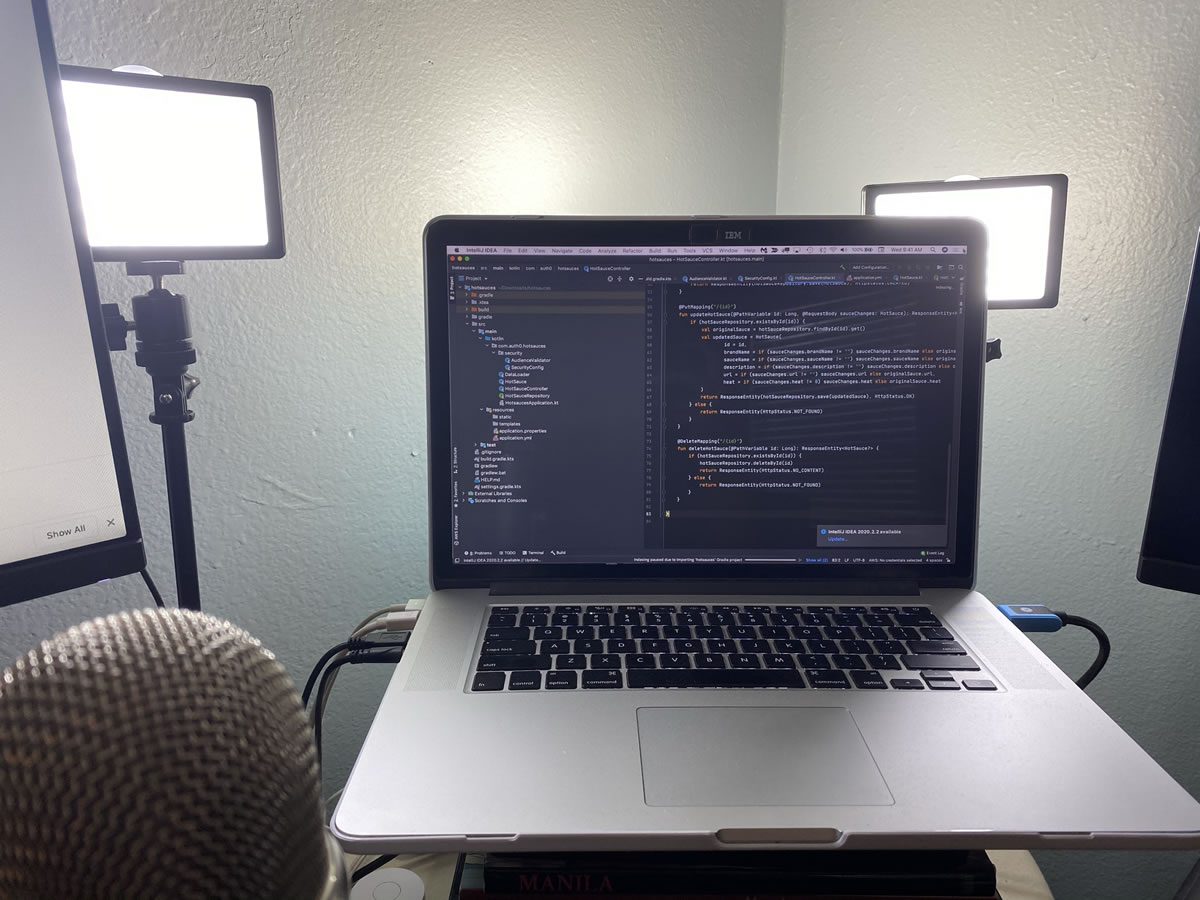
Tap to view the lighting setup at full size. For the really curious, the screen’s showing IntelliJ IDEA displaying a tech interview exercise in which I built an API of hot sauces using Spring Boot, Kotlin, and one other thing that I’ll name later.
It works quite well — and better than I expected. While it’s light and takes up little space once collapsed, it’s a little too flimsy for someone who needs on-the-go lighting.
However, if you plan on keeping the rig in just one place and not travel with it, it’s a good setup for your video chats, meetings, interviews, classes, and so on. Check it out on Amazon.
The lights worked well for last night’s class and the previous week’s tech interview. I’ll write more about how the interview went soon.
I need to look up this grill to see what its embedded controller does. Aside from…
reporting its current settings and temperature, and
some limited ability to control it remotely (very limited, if at all — the computers in IoT devices are cheap and insecure, and attackers can cause all sorts of mischief with a networked propane tank)…
…what else does it do that needs an update, never mind an update big enough to interfere with cooking?
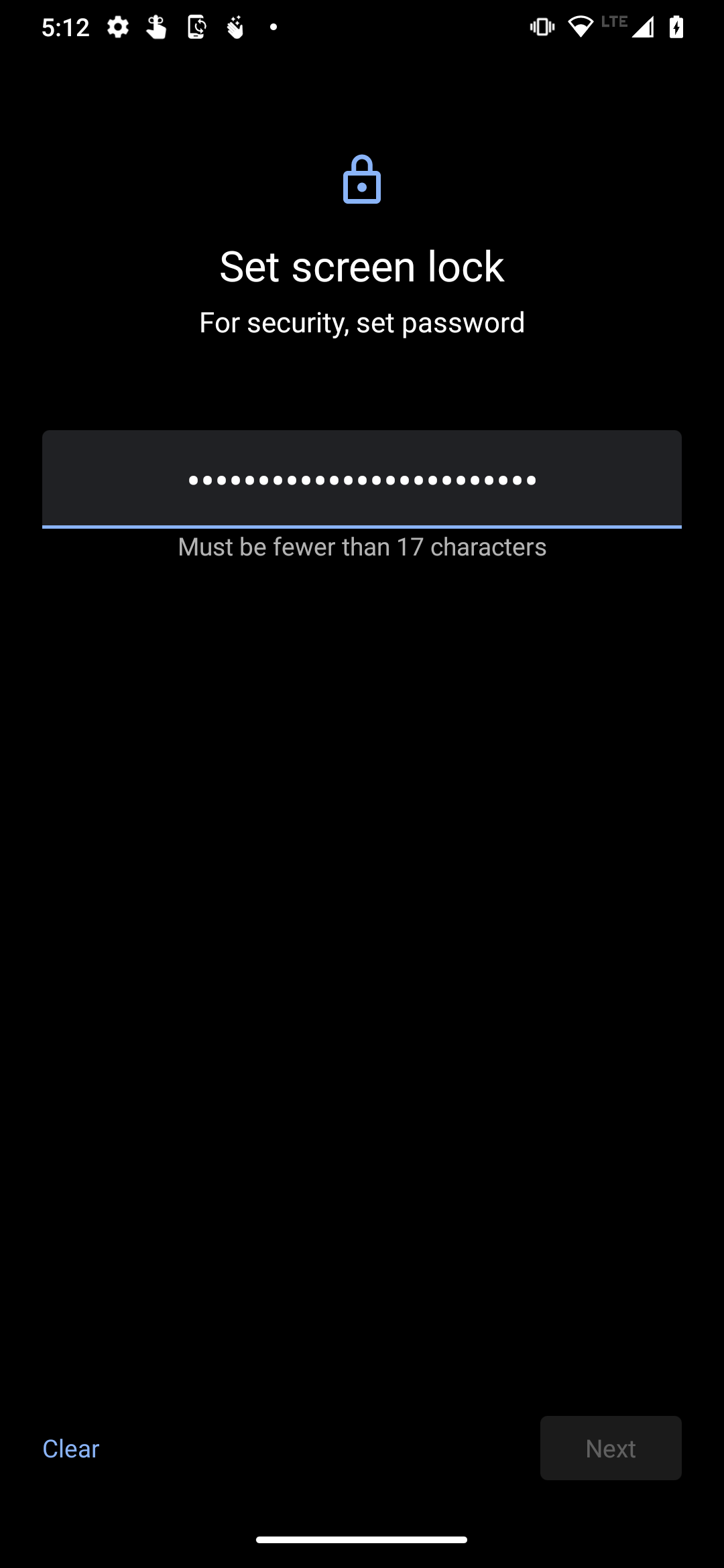
When it came time to set the passcode to unlock the phone, I found out that the longest device unlock passcode that even the most recent version of Android will accept is 16 characters.That was the case five years ago, and it’s still the case today.
Android’s “Choose Lock Password” screen is part of AOSP (Android Open Source Project), which means that its source code is easy to find online. It’s ChooseLockPassword.java, and the limitation is a constant defined in a class named ChooseLockPasswordFragment, which defines the portion of the screen where you enter a new passcode.
Here are the lines from that class that define passcode requirements and limitations:
private int mPasswordMinLength = LockPatternUtils.MIN_LOCK_PASSWORD_SIZE;
private int mPasswordMaxLength = 16;
private int mPasswordMinLetters = 0;
private int mPasswordMinUpperCase = 0;
private int mPasswordMinLowerCase = 0;
private int mPasswordMinSymbols = 0;
private int mPasswordMinNumeric = 0;
private int mPasswordMinNonLetter = 0;
Note the values assigned to these variables. It turns out that there are only two constraints on Android passcodes that are currently in effect:
The minimum length, stored in mPasswordMinLength, which is set to the value stored in the constant LockPatternUtils.MIN_LOCK_PASSWORD_SIZE. This is currently set to 6.
The maximum length, stored in mPasswordMaxLength, which is set to 16.
As you might have inferred from the other variable names, there may eventually be other constraints on passcodes — namely, minimums for the number of letters, uppercase letters, lowercase letters, symbol characters, numeric characters, and non-letter characters — but they’re currently not in effect.
Why 16 characters?
16 is a power of 2, and to borrow a line from Snow Crash, powers of 2 are numbers that a programmer would recognize “more readily than his own mother’s date of birth”. This might lead you to believe that 16 characters would be some kind of technical limit or requirement, but…
…Android (and in fact, every current non-homemade operating system) doesn’t store things like passcodes and passwords as-is. Instead, it stores the hashes of those passcodes and passwords. The magic of hash functions is that no matter how short or long the text you feed into them, their output is always the same fixed size (and a relatively compact size, too).
For example, consider SHA-256, from the SHA-2 family of hash functions:
No matter the length of the input text, the output of the SHA-256 function is always the same length: 64 characters, each one a hexadecimal digit.
Under the 16-character limit, the password will always be shorter than the hash that actually gets stored! There’s also the fact that in a time when storage is measured in gigabytes, we could store a hash that was thousands of characters long and not even notice.
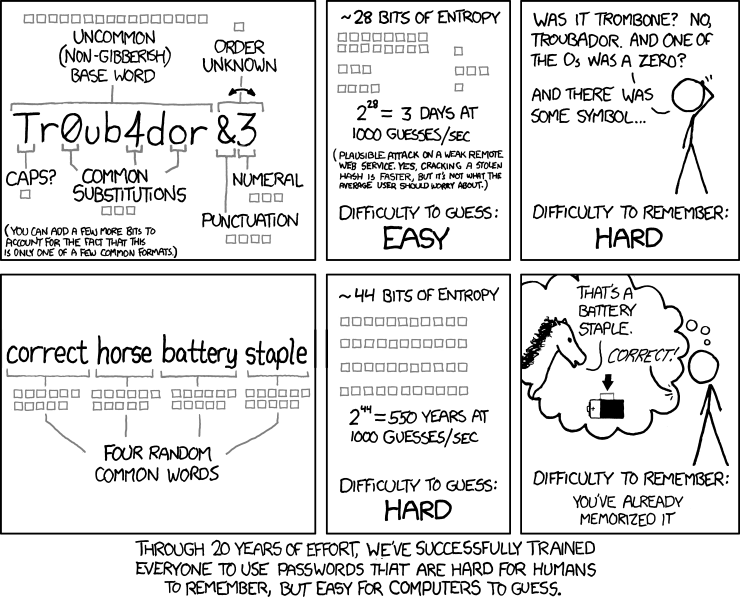
My guess is that the Android passcode size limit of 16 characters is purely arbitrary. Perhaps they thought that 16-character passwords like the ones below were the longest that anyone would want to memorize:
Based on usability factors, there is a point after which a password is just too long, but it’s not 16 characters. I think that iOS’ 37-character limit is more suitable.