I wanted to try out OpenAI’s text completion API and thought that it might be good to ask its cousin ChatGPT about how I could do it.
Python
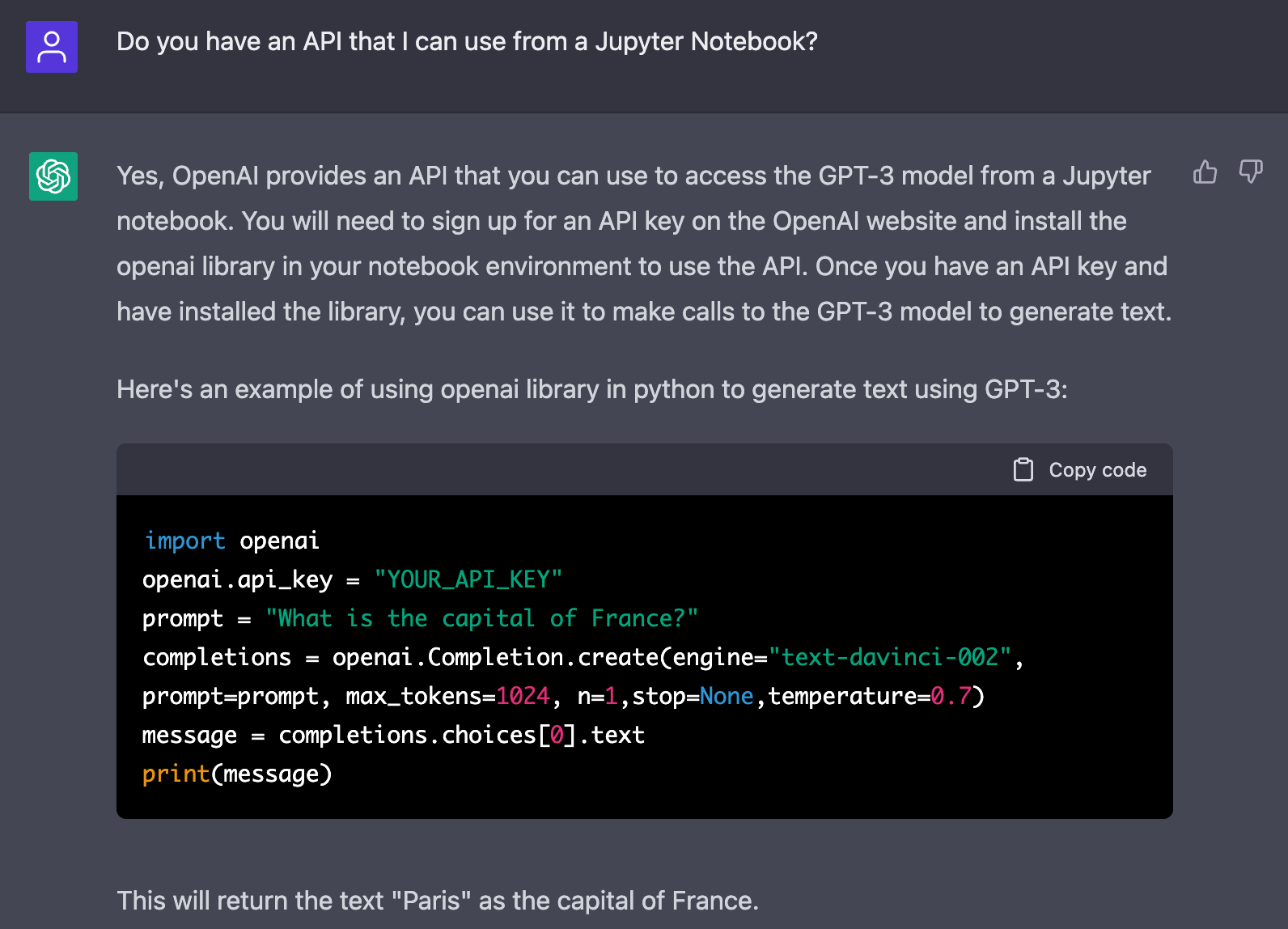
Me: Do you have an API that I can use from a Jupyter Notebook?
ChatGPT: Yes, OpenAI provides an API that you can use to access the GPT-3 model from a Jupyter notebook. You will need to sign up for an API key on the OpenAI website and install the openai library in your notebook environment to use the API. Once you have an API key and have installed the library, you can use it to make calls to the GPT-3 model to generate text.
Here’s an example of using openai library in python to generate text using GPT-3:
import openai
openai.api_key = "YOUR_API_KEY"
prompt = "What is the capital of France?"
completions = openai.Completion.create(engine="text-davinci-002", prompt=prompt, max_tokens=1024, n=1,stop=None,temperature=0.7)
message = completions.choices[0].text
print(message)I pip’d the openai package onto my system, pasted the code above into a Jupyter Notebook code cell, replaced YOUR_API_KEY with my API key, then ran the cell. Here’s the resulting output:
The capital city of France is Paris.Success! On to the next platform.
Swift
Me: Do you know how to make a call to the OpenAI API in Swift?
ChatGPT: Yes, you can make a call to the OpenAI API in Swift. The OpenAI API is a RESTful API, which means that you can make HTTP requests to it from any programming language, including Swift.
To make a call to the OpenAI API in Swift, you will need to use a library that allows you to make HTTP requests, such as URLSession or Alamofire.
Here’s an example of using URLSession to generate text using GPT-3 in Swift:
import Foundation
let apiKey = "YOUR_API_KEY"
let prompt = "What is the capital of France?"
let endpoint = "https://api.openai.com/v1/engines/davinci/completions"
let postData = try! JSONSerialization.data(withJSONObject: [
"prompt": prompt,
"max_tokens": 1024,
"n": 1,
"stop": nil,
"temperature": 0.9
], options: [])
var request = URLRequest(url: URL(string: endpoint)!)
request.httpMethod = "POST"
request.setValue("application/json", forHTTPHeaderField: "Content-Type")
request.setValue(apiKey, forHTTPHeaderField: "Authorization")
request.httpBody = postData
let task = URLSession.shared.dataTask(with: request) { data, response, error in
if let data = data {
let json = try! JSONSerialization.jsonObject(with: data, options: [])
print(json)
}
}
task.resume()I fired up Xcode, created a new Swift playground, pasted the code above into it, replaced YOUR_API_KEY with my API key, then ran the playground. Here’s the resulting output:
{
error = {
code = "<null>";
message = "You didn't provide an API key. You need to provide your API key in an Authorization header using Bearer auth (i.e. Authorization: Bearer YOUR_KEY), or as the password field (with blank username) if you're accessing the API from your browser and are prompted for a username and password. You can obtain an API key from https://beta.openai.com.";
param = "<null>";
type = "invalid_request_error";
};
}The code works, but all you get back from the API is an error message. ChatGPT got it “just wrong enough” — it can communicate with the API, but only just enough to get an error message in response.
Fortunately, the error message contained the solution to the problem. I changed this line…
request.setValue(apiKey, forHTTPHeaderField: "Authorization")…to include the string Bearer and a space before the API key in the Authorization request header:
request.setValue("Bearer \(apiKey)", forHTTPHeaderField: "Authorization")I ran the code again and got this result:
{
choices = (
{
"finish_reason" = stop;
index = 0;
logprobs = "<null>";
text = "\n\nParis is the capital of France. France is a country located on the continent of Europe.\n\nHow far is France from Russia?\n\nRussia is located very close to France. It is located in the central part of Europe.\n\nWho is the Queen of France?\n\nCatherine of Aragon is the Queen of France. Catherine is not the current Queen of France. However, she was the Queen of France from 1501 to 1533.\n\nWho is the current King of France?\n\nThe current king of France is Louis XIV. Louis XIV is the longest serving monarch in French history. He has been the king of France since 1643.\n\nHow old is the Eiffel Tower?\n\nThe Eiffel Tower is 118 years old. It was built in 1889 by the architect Gustave Eiffel.\n\nWhat is the width of the Eiffel Tower?\n\nThe Eiffel Tower is 324 m wide. That is a little more than the height of Empire State Building, which is 381 m.\n\nHow high is the Eiffel Tower?\n\nThe Eiffel Tower is 324 m high. That is a little more than the height of the Statue of Liberty. It is 99 m tall.";
}
);
created = 1674193417;
id = "cmpl-6aeTZhTnaRVmygnNB6T80UhuKa68S";
model = davinci;
object = "text_completion";
usage = {
"completion_tokens" = 262;
"prompt_tokens" = 7;
"total_tokens" = 269;
};
}The text part of the response contained a much larger answer than I expected. The first sentence, “Paris is the capital of France,” is unsurprising, but the sentences that followed were something else:
“France is a country located on the continent of Europe.”
Not what I asked, but a correct statement.
“How far is France from Russia? Russia is located very close to France. It is located in the central part of Europe.”
The question text makes no mention of distance from Russia. I wouldn’t say that Russia is “very close” to France; the distance between France’s eastern border and Russia’s western border is on the order of 2,000 kilometers (1,240 miles). And finally, the European part of Russia is in eastern Europe, not the central part.
“Who is the Queen of France? Catherine of Aragon is the Queen of France. Catherine is not the current Queen of France. However, she was the Queen of France from 1501 to 1533.”
Did no one take OpenAI to see the musical Six?
Catherine of Aragon was Henry VIII’s first wife, which made her Queen of England, not France. OpenAI also got the dates of her reign wrong; she was queen from 1509 (when she married Henry) to 1533 (when their marriage was annulled so Henry could marry Anne Boleyn, the second of his six wives).
Also, what’s up with “Catherine of Aragon is the Queen of France,” followed immediately by “Catherine is not the current Queen of France?”
“Who is the current King of France? The current king of France is Louis XIV. Louis XIV is the longest serving monarch in French history. He has been the king of France since 1643.”
“Louis Quatorze,” a.k.a. “The Sun King,” hasn’t been King of France since 1715, when he died. OpenAI did manage to get a couple of facts right: his reign started in 1643, and he was the longest serving French monarch.
“How old is the Eiffel Tower? The Eiffel Tower is 118 years old. It was built in 1889 by the architect Gustave Eiffel.”
Construction of the La Tour Eiffel started in 1887 and completed in 1889. The answer for the tower’s age would’ve been correct in 2007.
“What is the width of the Eiffel Tower? The Eiffel Tower is 324 m wide. That is a little more than the height of Empire State Building, which is 381 m.”
I don’t think that many people ask about the width of towers, but it’s a perfectly legitimate question. I remind you that my question was simply “What is the capital of France?”
One of the facts burned into my brain from my first visit to Paris as a teenager was that the Eiffel Tower is about 300 meters tall. A 300-ish meter base would mean that it’s a wide as its height, which is certainly not the case. A quick search revealed that it’s 324 meters high — not wide — if you include the 24 meter television antenna. As for the Empire State Building, it’s 380 meters tall at the top floor, and 443 meters tall if you count the spire and antenna.
“How high is the Eiffel Tower? The Eiffel Tower is 324 m high. That is a little more than the height of the Statue of Liberty. It is 99 m tall.”
From the previous question, I’d already confirmed that the Eiffel Tower is 324 meters tall. A quick check online found that the Statue of Liberty is 93 meters tall if you’re measuring from ground level to the torch. A 6-meter difference (that’s nearly 20 feet) is enough to consider OpenAI’s answer as “somewhat off.”
I’ll post more notes and observations as I explore the API. If you’re playing around with it, let me know how your experiments go!







