This time, it was on Zoom, so I had more than one reason to dress up.
I think it went pretty well.
This time, it was on Zoom, so I had more than one reason to dress up.
I think it went pretty well.

 In my article about the Capture the Flag at The Undercroft in which I recently participated, I wrote about my solution to this particular challenge:
In my article about the Capture the Flag at The Undercroft in which I recently participated, I wrote about my solution to this particular challenge:
Your answer lies in the 1’s and 0’s…
0010111 00001111 00010111, 00011001 00001111 10101 00000001 00010010 00000101 00010010 00001001 00000111 00001000 00010100(Make sure to use the comma, and spaces correctly)
The first part of my solution was turning those numbers into a list. Copy the numbers into a text editor, stick 0b in front of each one, and then turn the sequence into a Python list:
numbers = [0b0010111, 0b00001111, 0b00010111, 0b00011001, 0b00001111, 0b10101, 0b00000001, 0b00010010, 0b00000101, 0b00010010, 0b00001001, 0b00000111, 0b00001000, 0b00010100]
Paste the list into a Python REPL and then display its contents to see the numbers in decimal:
>>> numbers [23, 15, 23, 25, 15, 21, 1, 18, 5, 18, 9, 7, 8, 20]
The next step is to convert those numbers into letters. Once again, the Unicode/ASCII value for “A” is 65, so the trick is to add 64 to each number and convert the resulting number into a character.
Here’s how I did that:
>>> characters = map(lambda number: chr(number + 64), numbers) >>> list(characters) ['W', 'O', 'W', 'Y', 'O', 'U', 'A', 'R', 'E', 'R', 'I', 'G', 'H', 'T']
I could’ve gone super-functional and done it in one line:
>>> list(map(lambda number: chr(number + 64), numbers)) ['W', 'O', 'W', 'Y', 'O', 'U', 'A', 'R', 'E', 'R', 'I', 'G', 'H', 'T']
Between lambda and map(), there’s a whole lot of functional programming concepts to solve a relatively simple problem.
I could write a whole article — and I probably should — based on just that single line of code, but in the meantime, I thought I’d post an easier, more Pythonic solution.
This simpler solution uses good ol’ list comprehensions:
>>> characters = [chr(number + 64) for number in numbers] >>> characters ['W', 'O', 'W', 'Y', 'O', 'U', 'A', 'R', 'E', 'R', 'I', 'G', 'H', 'T']
Most programming languages don’t have list comprehensions. In those languages, if you want to perform some operation on every item in an array, you use a mapping function, typically named map(), but sometimes collect() or select().
Hence my original solution with lambda and map() — it’s force of habit from working in JavaScript, Kotlin, Ruby, and Swift, which don’t have Python’s nifty list comprehensions.
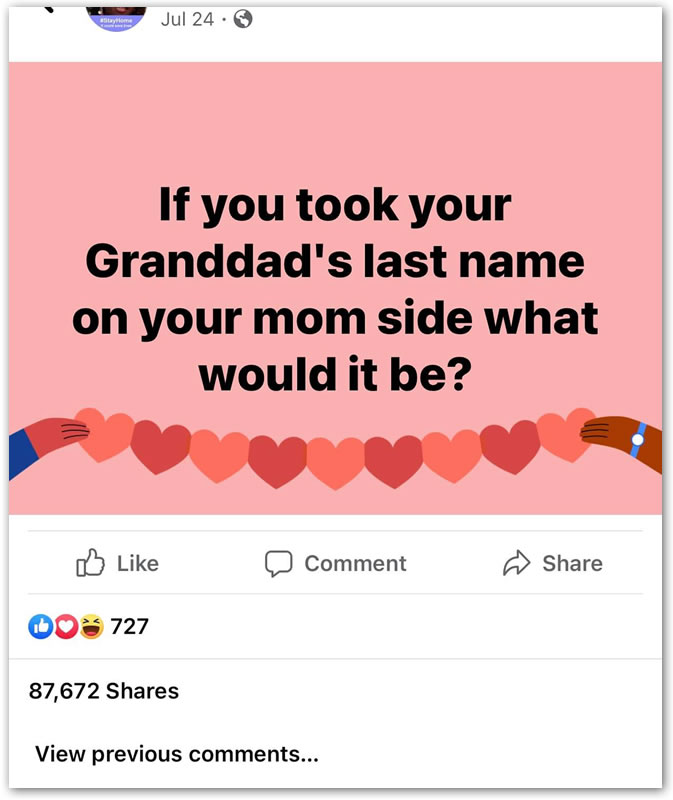
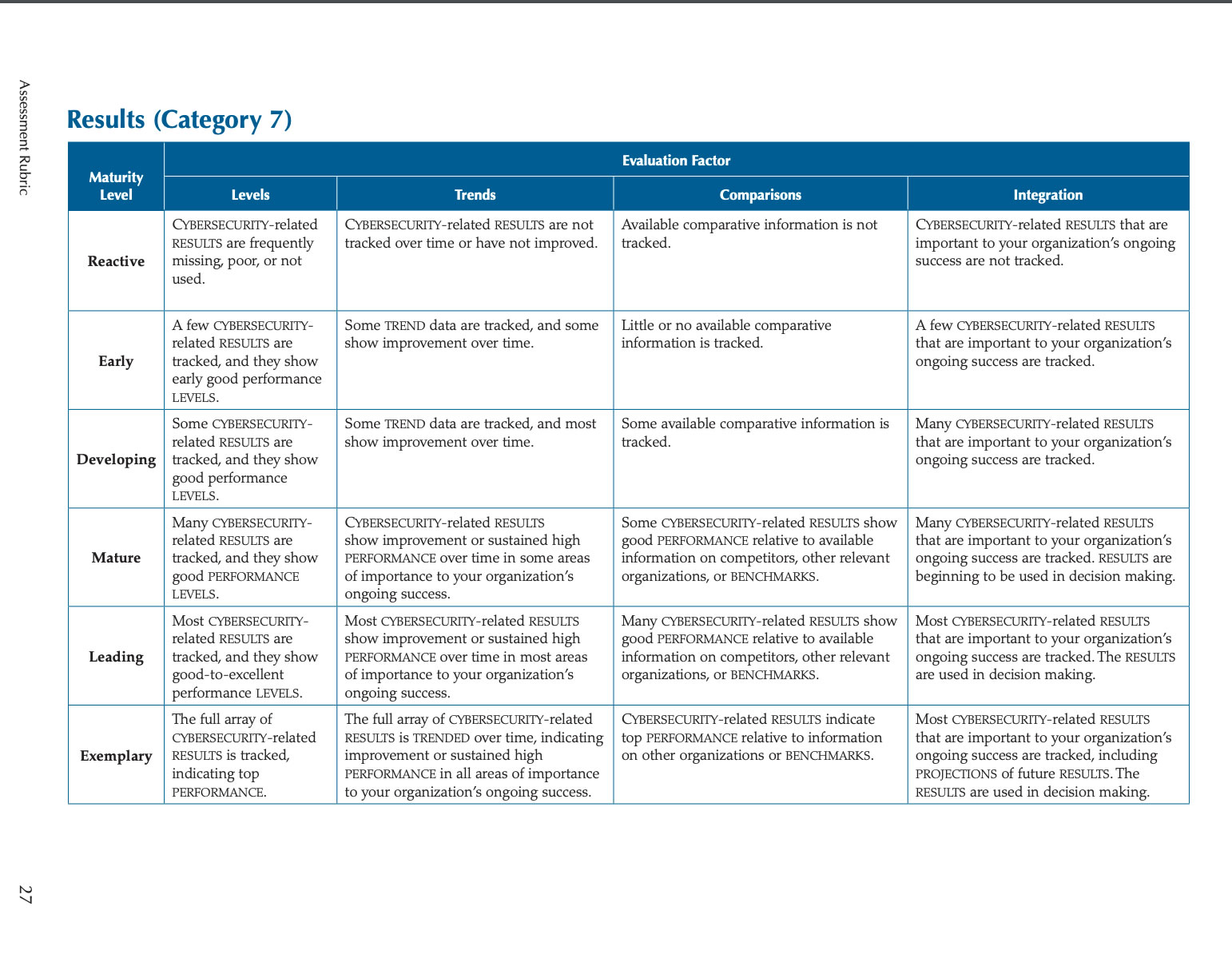
Look at that stat: 87,672 shares. I wonder how many people posted an answer.
I should come up with a list of the other common security questions, cleverly re-phrased.

The final event of UC Baseline, The Undercroft’s cybersecurity training program, was the Capture the Flag competition, which took place last Friday morning.
 In computing “Capture the Flag” events, the flag isn’t a physical one, but some kind of challenge. Sometimes, it’s something you need to retrieve from a program, website, or even a piece of hardware with an intentionally built-in vulnerability that you must exploit. Sometimes it’s a problem or puzzle you must solve. It may also be a trivia challenge.
In computing “Capture the Flag” events, the flag isn’t a physical one, but some kind of challenge. Sometimes, it’s something you need to retrieve from a program, website, or even a piece of hardware with an intentionally built-in vulnerability that you must exploit. Sometimes it’s a problem or puzzle you must solve. It may also be a trivia challenge.
Solving each challenge earns you a specified number of points, with the tougher challenges being worth more points. The player with the most points wins.
Since it wasn’t scheduled as a day of actual class — the last day of class was on Wednesday — I’d booked a doctor’s appointment for that morning. A plumbing problem also required me to be at home for a little bit.

By the bye, if you’re looking for a great plumber in Tampa, I highly recommend Joshua Tree Plumbing.
Still, since most of the challenges were posted online and since I’d never participated in a CTF before, I decided to try anyway. I decided to treat my schedule as if it was a golfer’s handicap. Since some of the challenges were just questions where you’d either select an answer or type one in, I did them on my phone while waiting for the doctor.
In between a couple of car trips, I managed to eke out a little over an hour and a half of time in the CTF, so I think I placed rather well, all things considered:
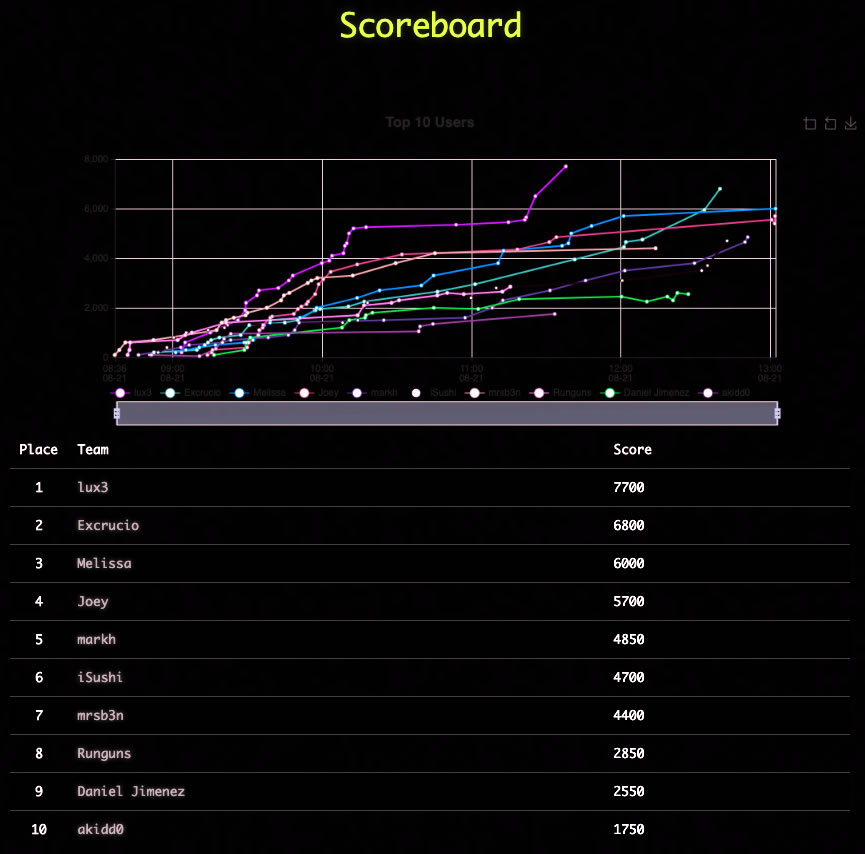 Here’s a sampling of some of the challenges:
Here’s a sampling of some of the challenges:
nmap [scan type] [ options] [target]
I solved a couple of the challenges with Python, and I’m sharing them here (with the permission of the instructors, of course):
Your answer lies in the 1’s and 0’s…
0010111 00001111 00010111, 00011001 00001111 10101 00000001 00010010 00000101 00010010 00001001 00000111 00001000 00010100(Make sure to use the comma, and spaces correctly)
My first instinct was to copy these numbers, into a text editor, stick 0b in front of each one, and then turn the sequence into a Python list:
numbers = [0b0010111, 0b00001111, 0b00010111, 0b00011001, 0b00001111, 0b10101, 0b00000001, 0b00010010, 0b00000101, 0b00010010, 0b00001001, 0b00000111, 0b00001000, 0b00010100]
I pasted the list into a Python REPL and then displayed its contents, to see the numbers in decimal:
>>> numbers [23, 15, 23, 25, 15, 21, 1, 18, 5, 18, 9, 7, 8, 20]
All the numbers were between 1 and 26 inclusive, suggesting letters of the alphabet.
The ASCII/Unicode value for “A” is 65. If you offset the numbers by adding 64 to each, and then convert each number to a character, you should get the message:
>>> characters = map(lambda number: chr(number + 64), numbers) >>> list(characters) ['W', 'O', 'W', 'Y', 'O', 'U', 'A', 'R', 'E', 'R', 'I', 'G', 'H', 'T']
Remembering the instructions to “use the comma, and spaces correctly,” the answer is:
WOW, YOU ARE RIGHT
Using the Linux OS and boot method of your choice (VM or live boot):
Create a folder. In that folder, create 100 directories that are uniquely named incrementally (ergo directory1, directory2, etc.). Inside each of those 100 directories, create 100 directories that are uniquely named incrementally. Inside each of those 100 directories, create 100 files named incrementally (file1, file2, file3, etc.). The contents of each file should include the lyrics to the “Battle Hymn of the Republic” by Julia Ward Howe.
When complete, show a staff member.

This challenge is phrased in such a way that it could only have been written by our Linux instructor Cochise (pictured to the right).
Creating those 100 directories in Linux is a one-liner:
mkdir directory{1..100}
The rest of the task calls for some scripting.
I’m terrible at shell scripting. I’m perfectly comfortable with using the shell interactively, in that classic enter-a-line/get-a-response fashion. However, once I have to deal with those half-baked control structures, I tend to walk away and say “Forget this — I’m doing it in Python.”
Here’s a cleaned-up, easier to read version of my solution to the challenge. It assumes that there’s a file called battle.txt in the same directory, and that the file contains the lyrics to the Battle Hymn of the Republic:
import os
import shutil
import sys
for directory_number in range (1, 101):
# Create the directory.
directory_name = f"directory{directory_number}"
try:
os.mkdir(directory_name)
except:
error = sys.exc_info()[0]
print(f"Failed to create directory {directory_name}.\n{error}")
quit()
# Go into the newly-created directory.
os.chdir(directory_name)
# Create the files within the directory
# by copying battle.txt from the directory above
# 100 times, naming them file1...file100.
for file_number in range(1, 101):
filename = f"file{file_number}"
try:
shutil.copy("../battle.txt", f"file{file_number}")
except:
error = sys.exc_info()[0]
print(f"Failed to create file {filename}.\n{error}")
quit()
# Let’s go back up one directory level,
# so that we can create the next directory.
os.chdir("..")
I had a lot of fun on my first CTF, even if I got to take part in a fraction of it. I’ll have to join The Undercroft’s next one!

All dressed up for a 📱 PHONE ☎️ interview. Sure, they won’t know I’m dressed up, but I’LL KNOW.

…wait until your IoT grill does it.
I need to look up this grill to see what its embedded controller does. Aside from…
…what else does it do that needs an update, never mind an update big enough to interfere with cooking?

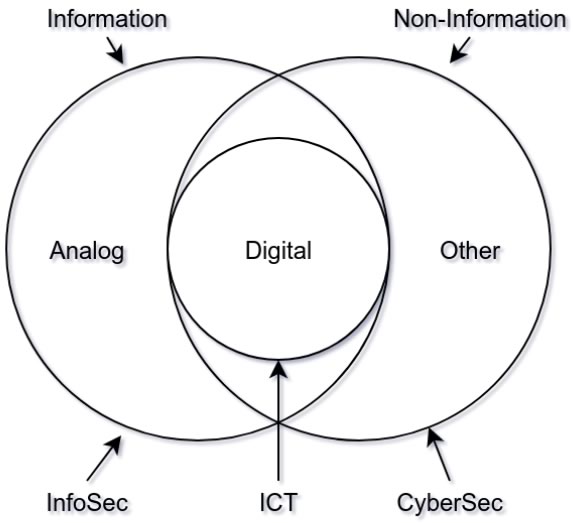
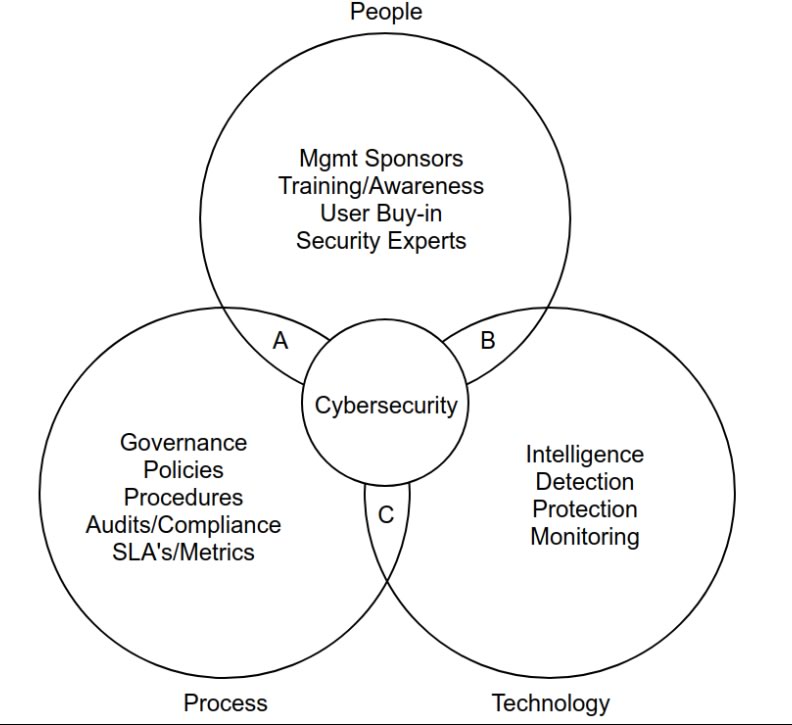
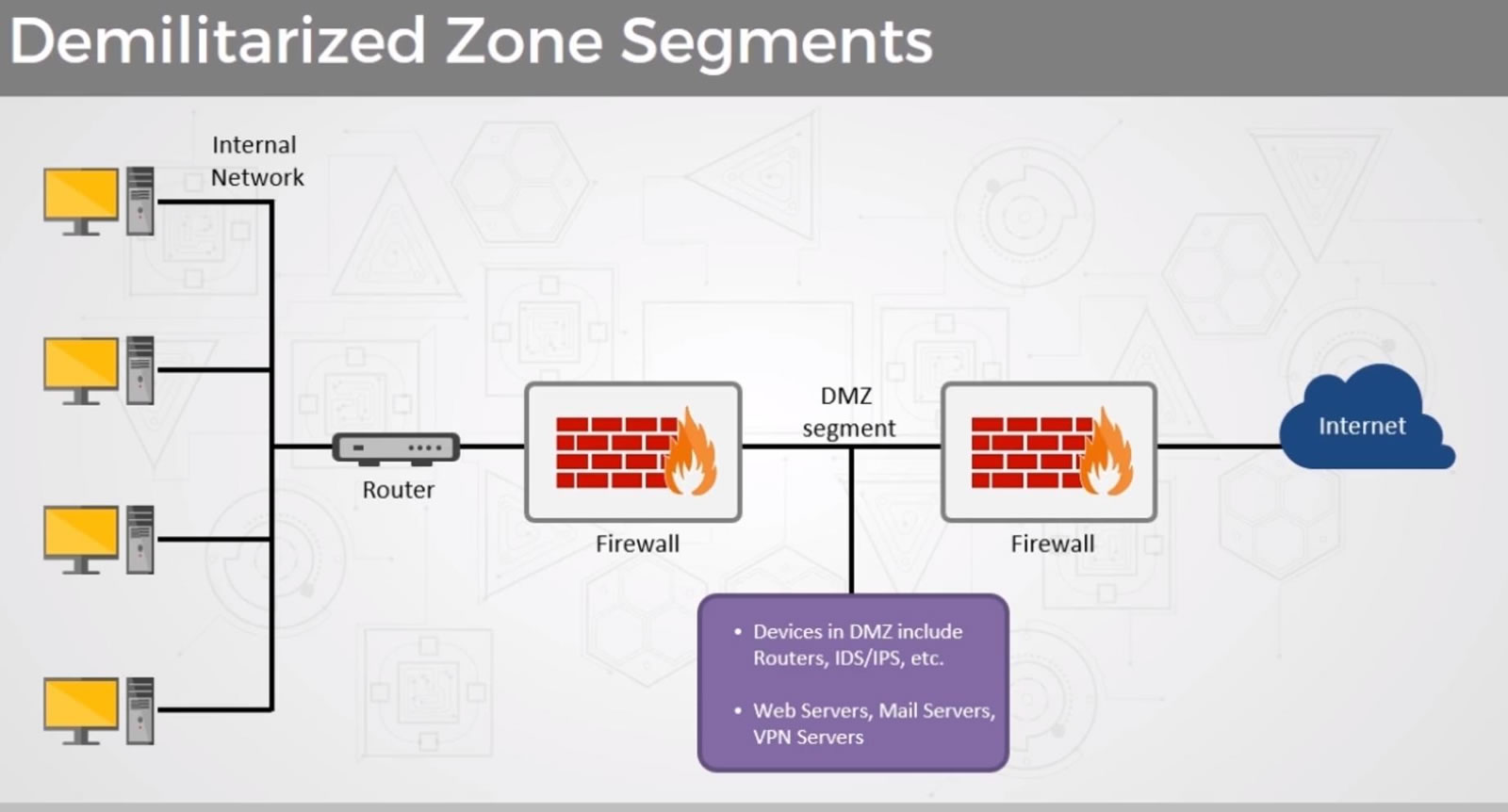
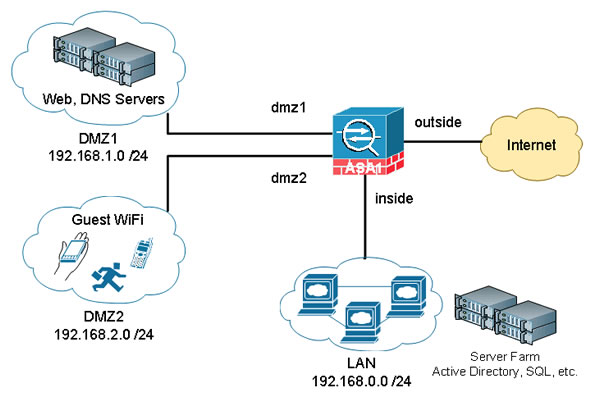
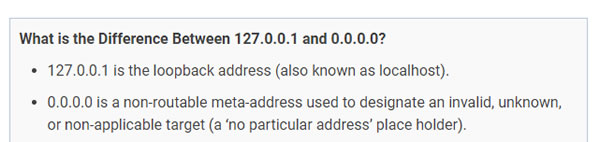
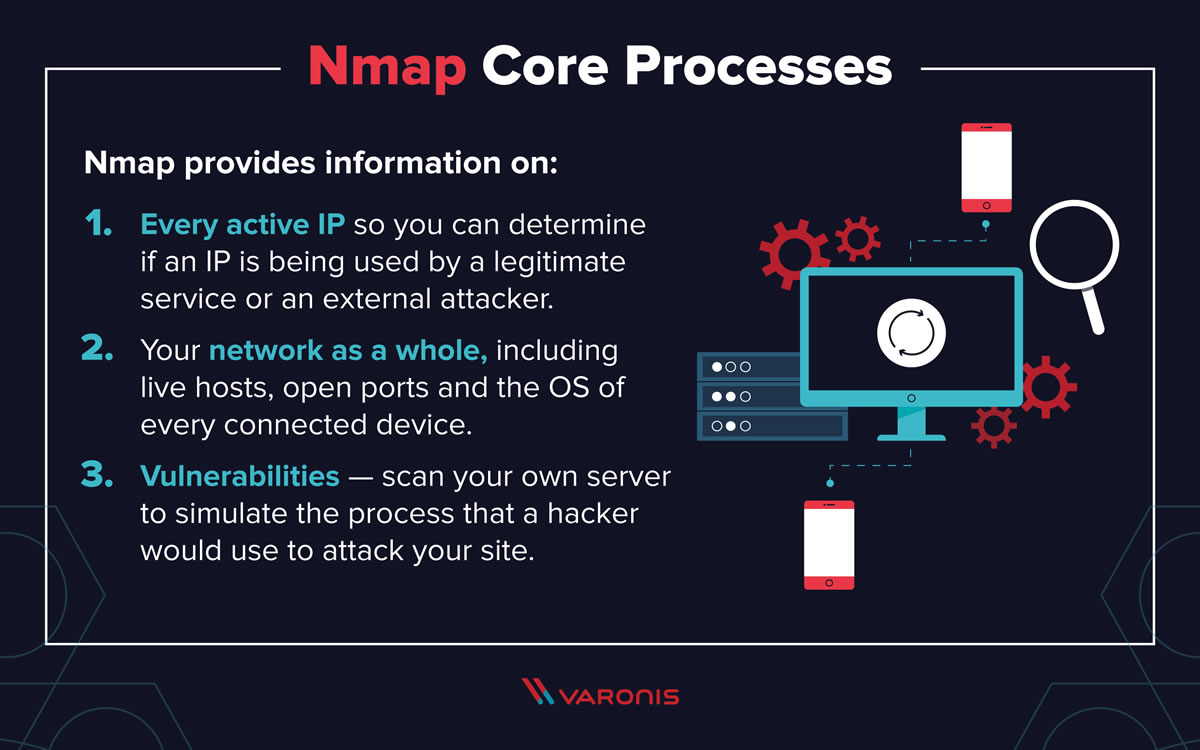
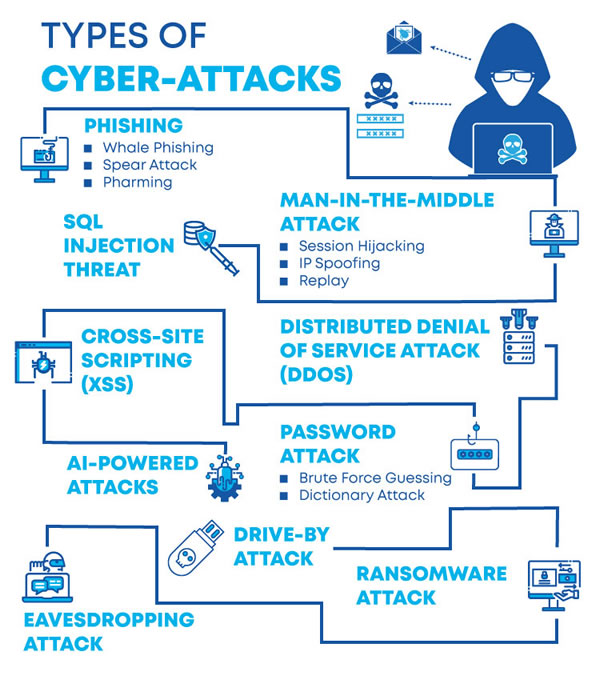
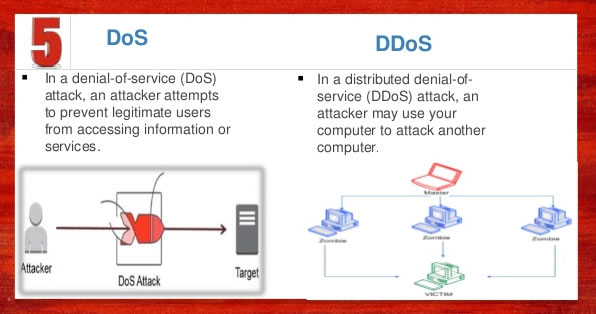
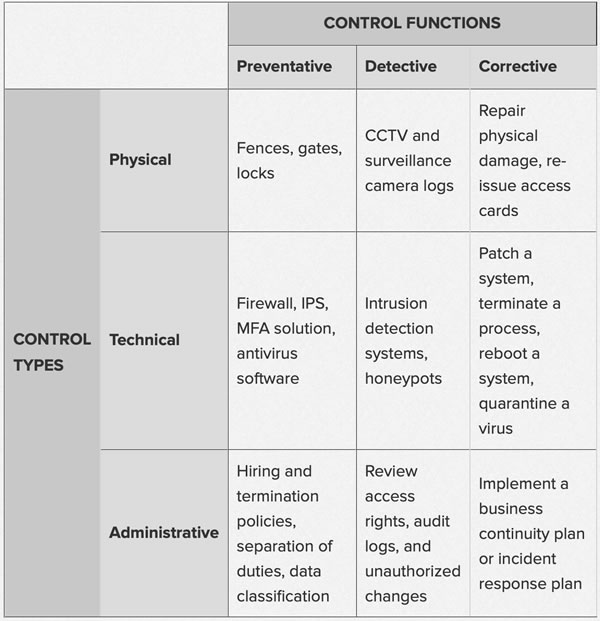
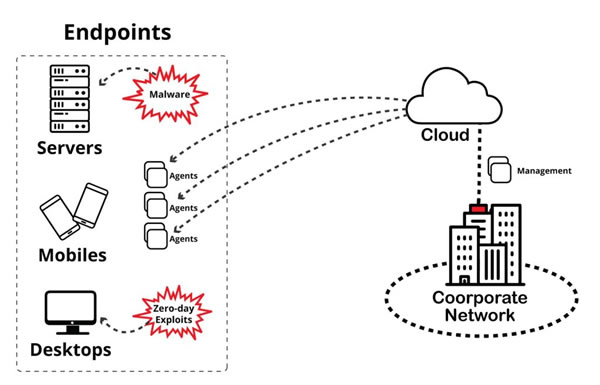
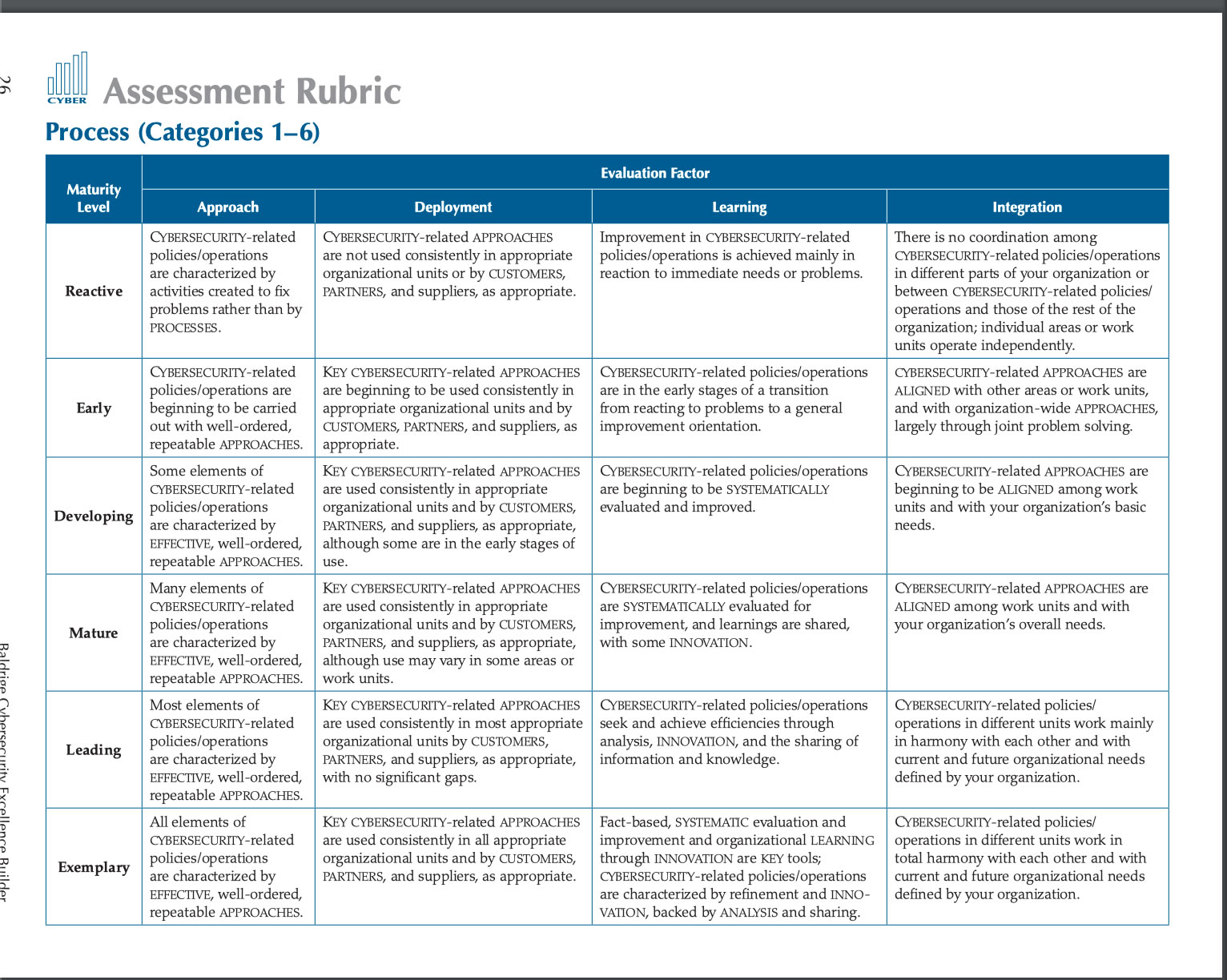
 During the Information Security week of the UC Baseline cybersecurity program, the instructors asked us a lot of questions whose answers we had to look up. As a way to maximize participation, we were encouraged to share lots of links of the class’ Slack channel, which also functioned as a backchannel, as well as a way to chat with the students who were taking the course online.
During the Information Security week of the UC Baseline cybersecurity program, the instructors asked us a lot of questions whose answers we had to look up. As a way to maximize participation, we were encouraged to share lots of links of the class’ Slack channel, which also functioned as a backchannel, as well as a way to chat with the students who were taking the course online.
The links that we shared in class were valuable material that I thought would be worth keeping for later reference. I’ve been spending an hour here and there, gathering them up and even organizing them a little. The end result is the list below.
Since these are all publicly-available links and don’t link to any super-secret UC Baseline instructional material, I’m posting them here on Global Nerdy. Think of this list as a useful set of security-related links, something to read if you’re bored, or a peek into what gets discussed during the InfoSec week of the UC Baseline course!