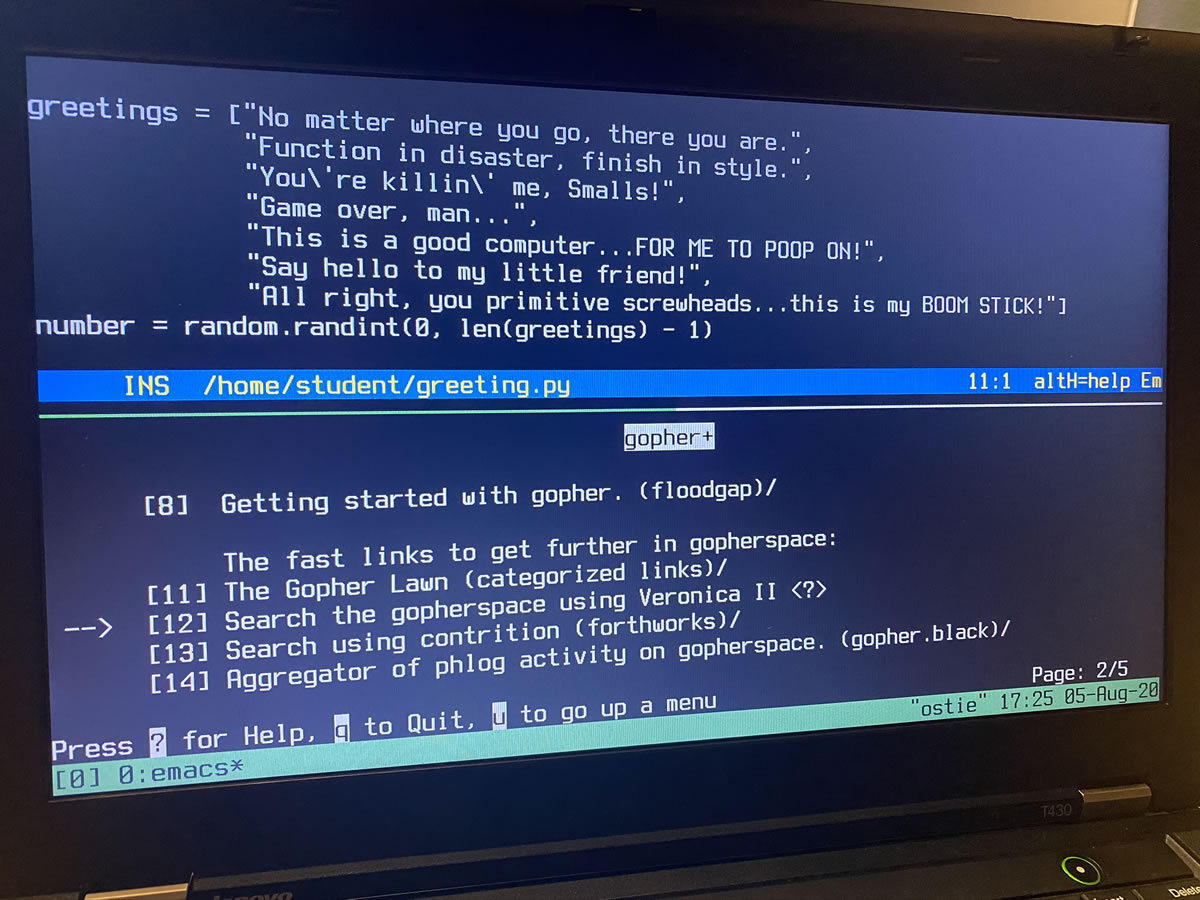
Last week was week 3 of the inaugural class of UC Baseline, the 5-week cybersecurity program offered by Tampa Bay’s security guild/coworking space/clubhouse for merry tech pranksters The Undercroft.
Last week was week 3 of the inaugural class of UC Baseline, the 5-week cybersecurity program offered by Tampa Bay’s security guild/coworking space/clubhouse for merry tech pranksters The Undercroft.
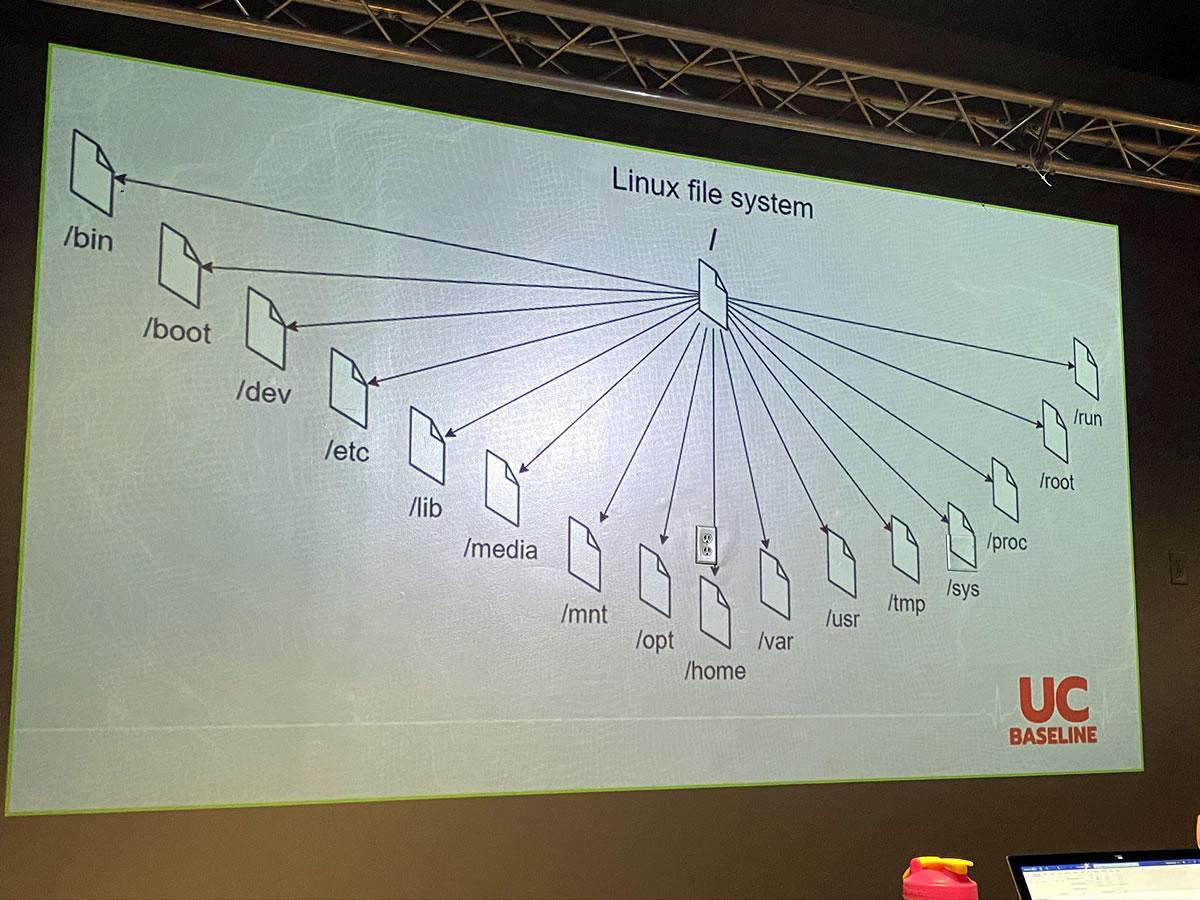
This week has been all about operating systems, and Monday to Wednesday were devoted to Linux (which I wrote about earlier). The remainder of the week, Thursday and Friday, were set aside for that contradiction in terms known as Windows security.
Here are some photos from the Windows Security days…
For this class, we moved from the room at the front of The Undercroft to the one in the back. Once again, I took my preferred perch — in the back row, on the left side of the room:

I have good reasons for picking the classroom seat favored by the “bad students”:
- It provides a view of the entire room at a single glance.
- With nobody behind me, only I see what’s on my laptop screen(s).
- It puts me upwind from everyone’s breathing. We are still in a pandemic, after all, and while we’re wearing masks and following precautions as best we can, we’re spending long hours in a classroom. We get tired. We get careless. Our hygiene game is one thing when we arrive fresh and rarin’ to go at 8:00 a.m. and a completely different thing at 4:02 p.m., after absorbing the finer points of processors, or the SYN/ACK/RST dance, or any other concept that the instructors are firehosing at us.
Some of the topics we covered were relatively straightforward and easy enough for laypeople to grasp…
…while others were subjects of Windows arcana that I haven’t dealt with in depth since my time at Microsoft:

Windows security is much more than just the technology. As the best-known, most-deployed, most-used (and yes, most-pirated) desktop operating system out there, you have to have a clear picture of who the targets are:

Windows Defender — actually, as of May 2020, it’s been going by its new name, Microsoft Defender — was part of the curriculum. It’s come a long way from the Windows XP days.

A good chunk of the Windows Security portion of the program was devoted to “living off the land” — LotL for short — which is a great metaphor for a specific type of attack strategy.

Living off the land is attacking a system by using tools, software, or features that already exist in the target environment. It’s using your victim’s own resources to break into their systems.
Living off the land offers a number of advantages:
- It makes it easier to avoid detection. All software leaves some kind of trace to one degree or another, and unfamiliar software performing unusual tasks usually attracts the attention of sysadmins. Familiar software that’s already on a target system tends to raise less suspicion. If you can harness software that’s already on the target system, it’s like having someone on the inside.
- It can be difficult to install malware on a target system. Even on systems managed by people who aren’t all that careful, it can still be difficult to gain enough access to install applications on a target system without authorization.
- The tools for administering systems are powerful, and they’re often pre-configured for easy access to the systems they’re on. If you’re an administrator, one of your performance metrics is how quickly you solve users’ problems. You’re incentivized to have software and utilities set up in such a way that you can get into their systems and change settings quickly. If you can access these, you’ve got a great attack vector.
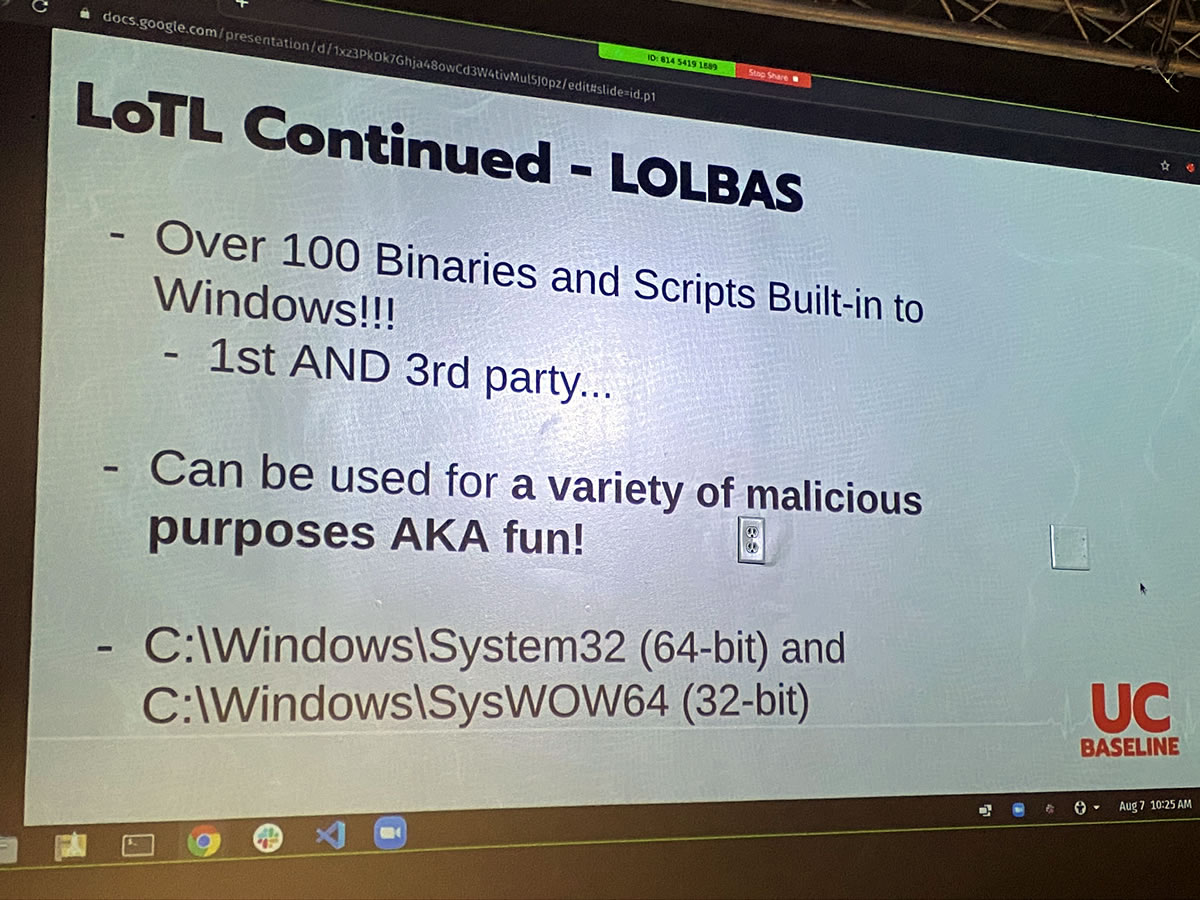
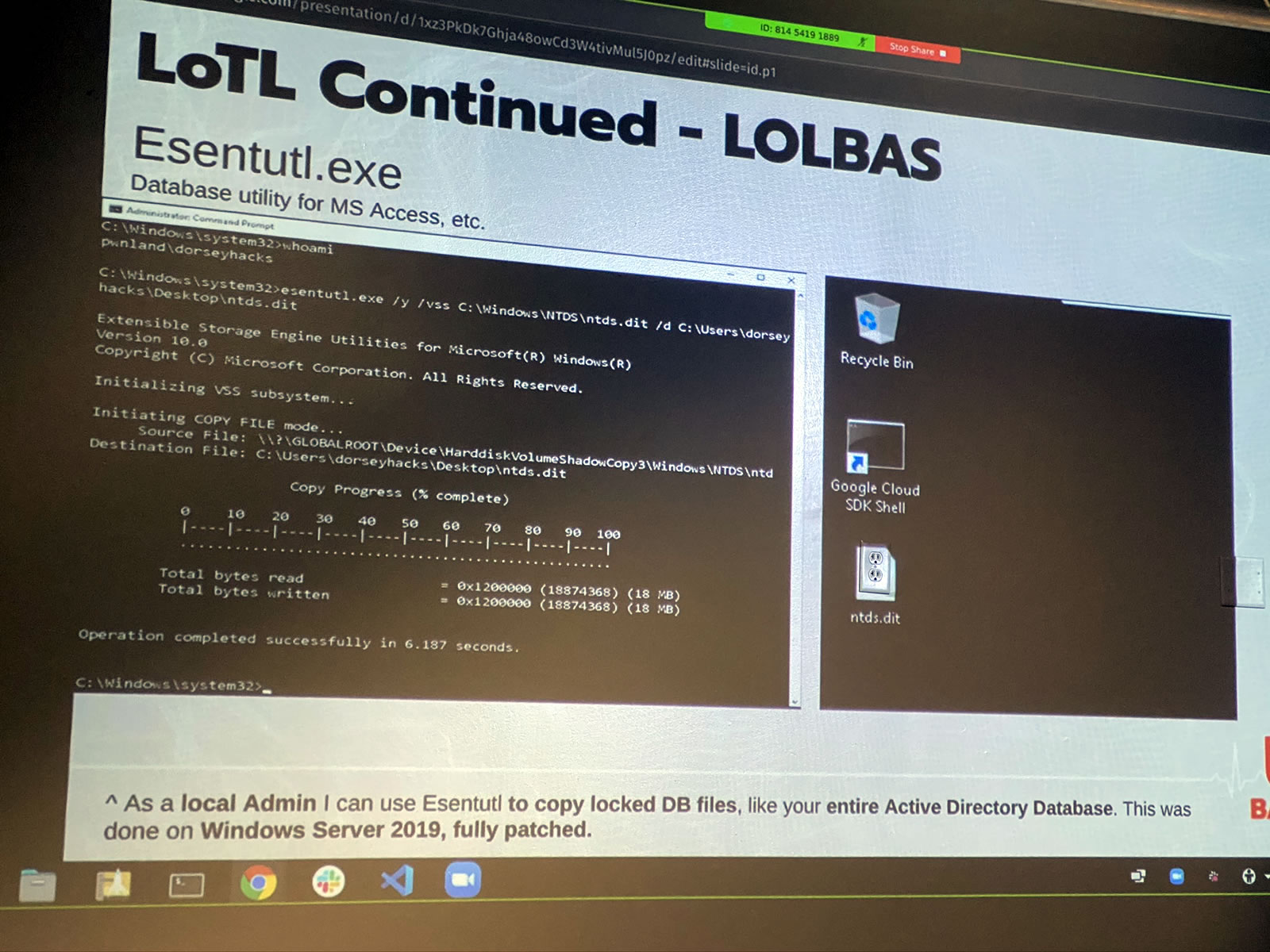
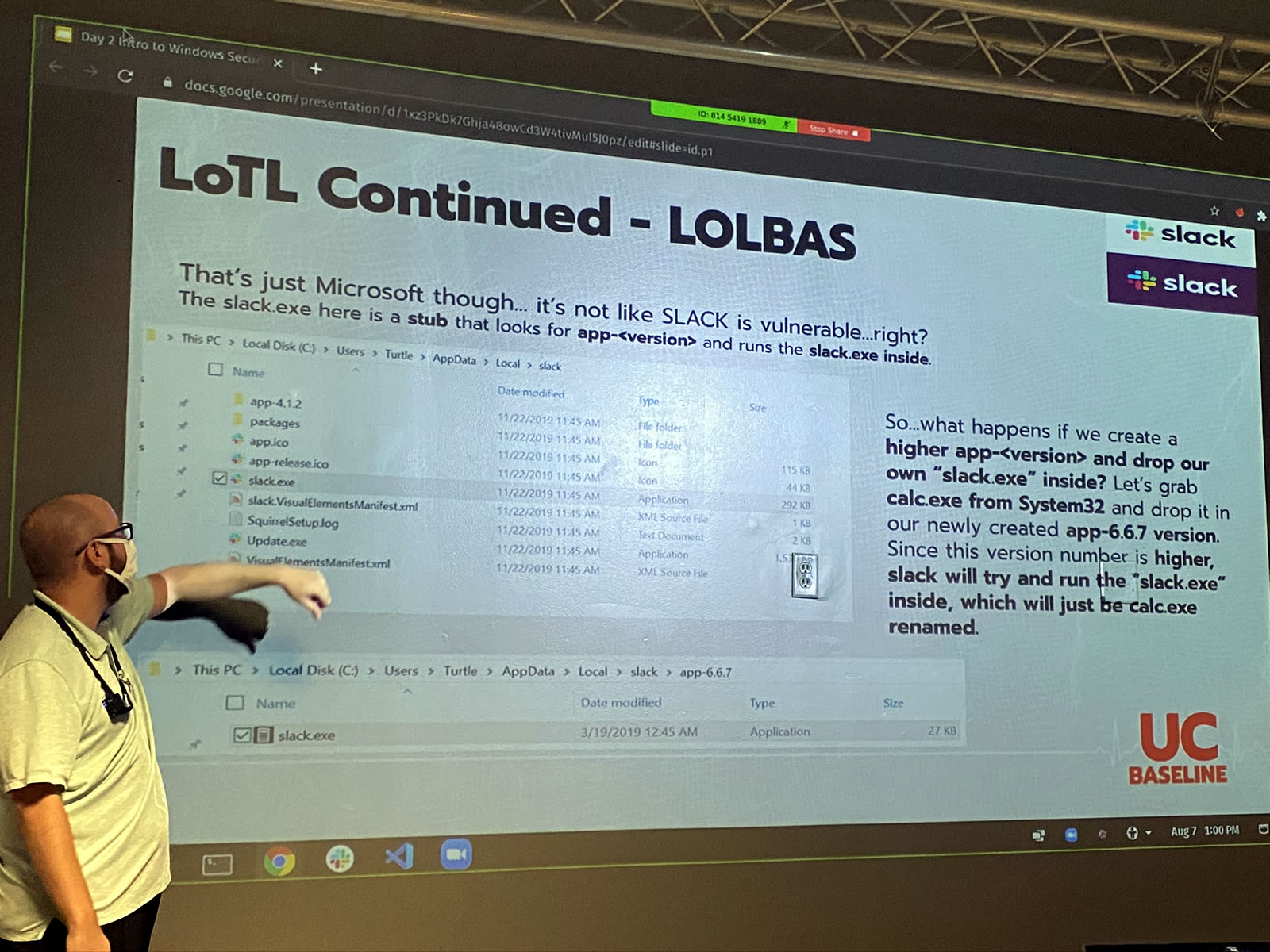
Living off the land is so effective that there’s now an entire suite of tools for it: LOLBAS, which is short for Living off the Land Binaries and Scripts. It’s a set of over 100 tools for living off the land on Windows systems — and ironically enough, it’s hosted on GitHub, which is a Microsoft property.
For these two days, we needed to be running Windows. My ThinkPad runs Mint Linux, but with VMWare and a Windows 10 VM, I was running Windows within Mint. And then, we remote desktopped into another Windows machine, which meant I was running Windows from Windows from Linux:
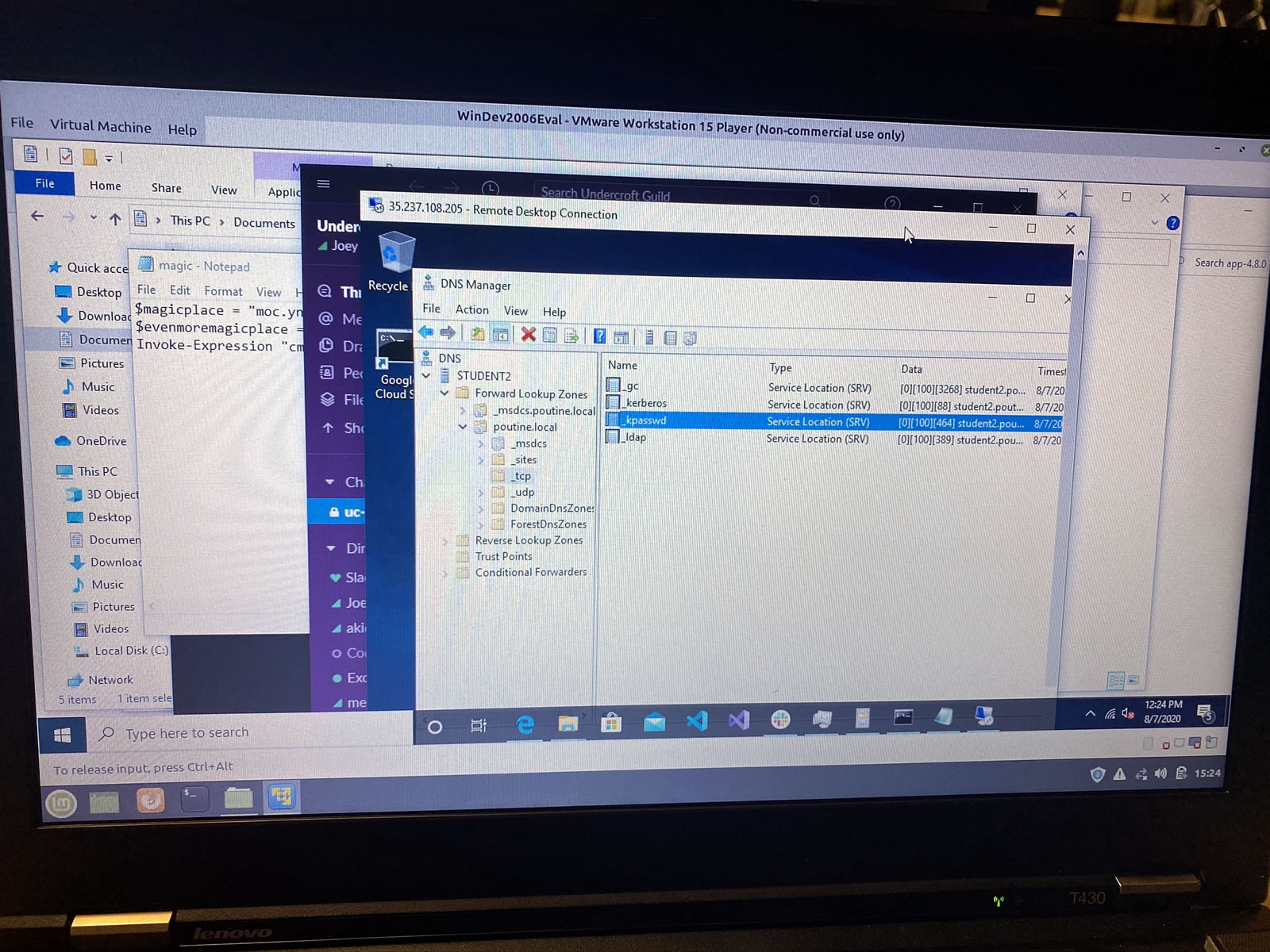
I haven’t done this sort of Windows systems admins since I worked at the Beast of Redmond:
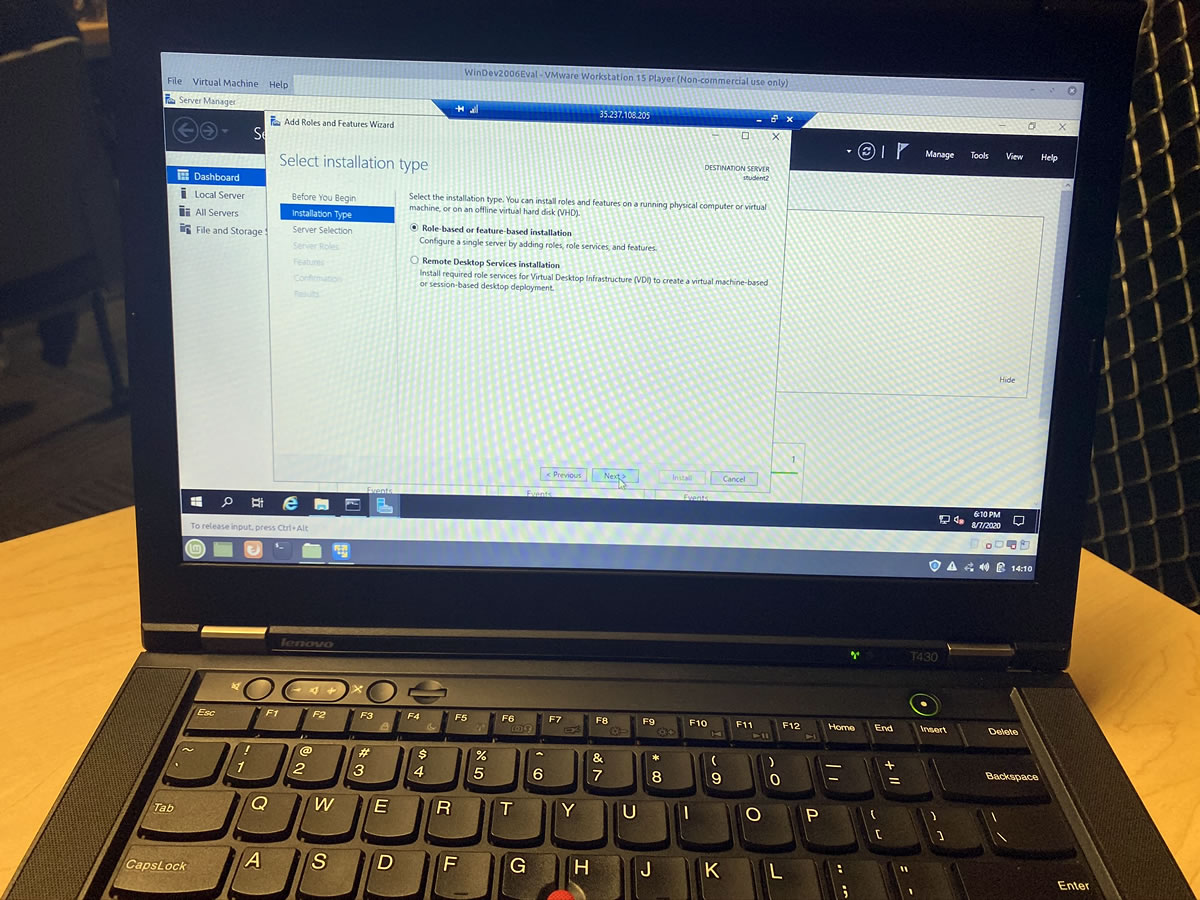
Let’s give this remote system’s domain a proper name…
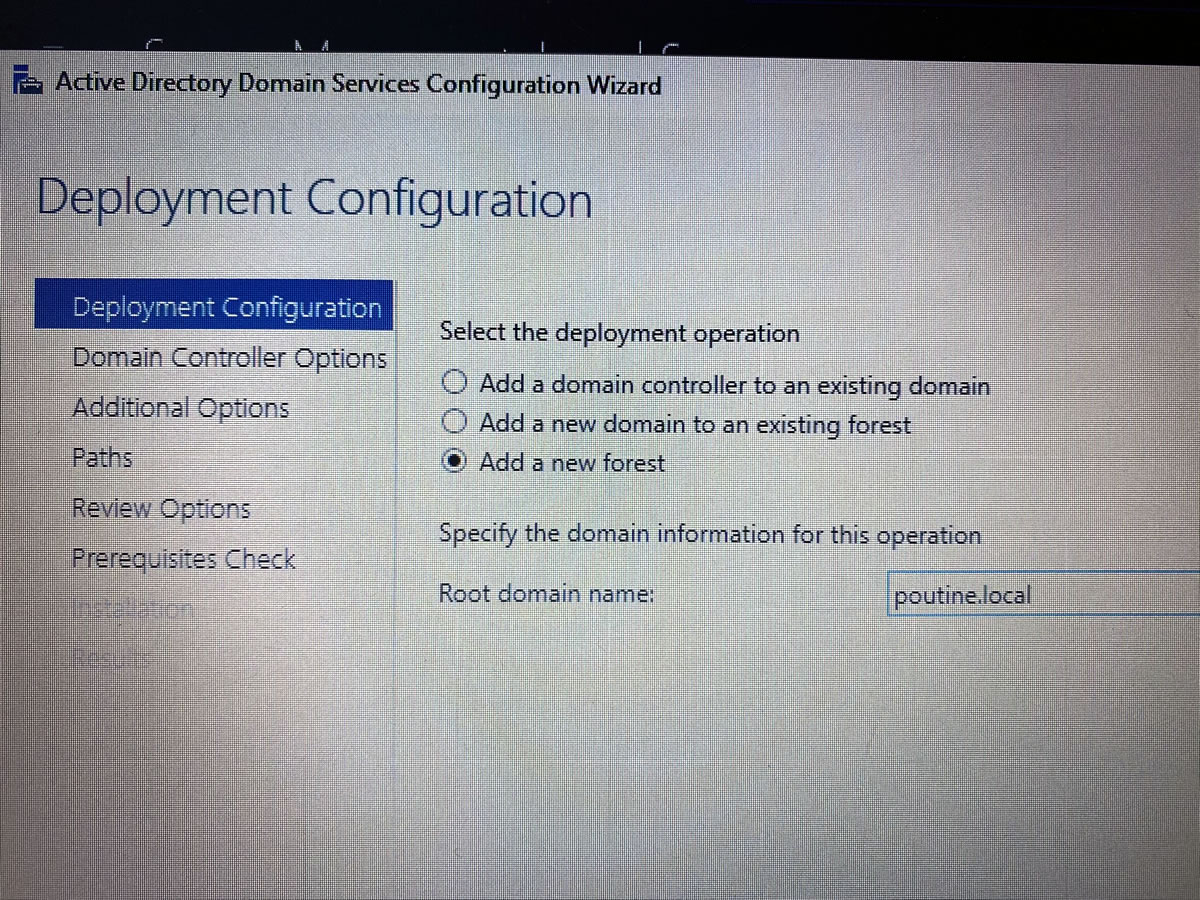
…and a proper admin password as well. Remember, 668 is the Neighbor of the Beast:
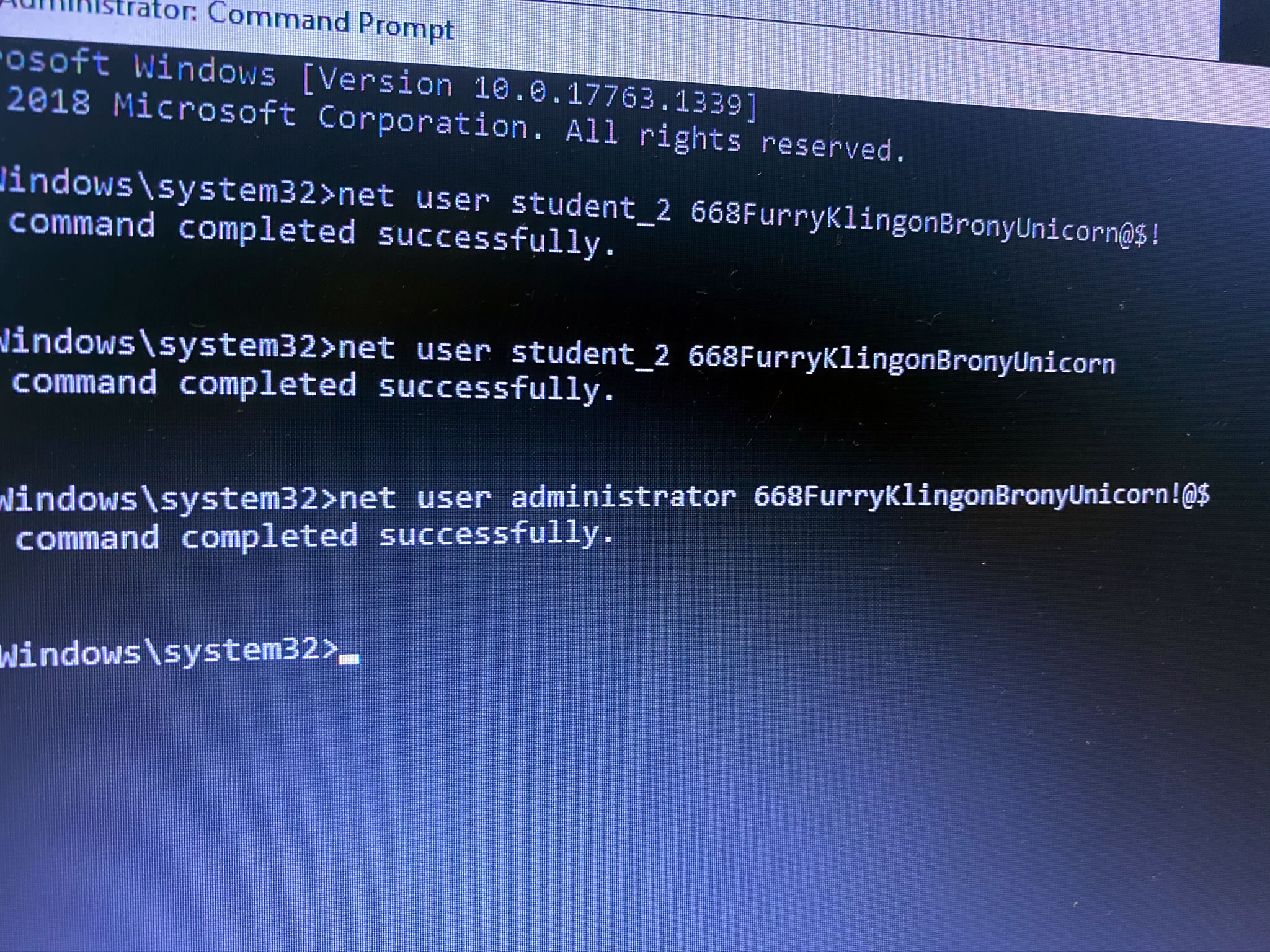
Although we were free to play with this remote system, I will still neither confirm nor deny that I may have left little scripts that will automatically and unwillingly take unsuspecting users directly to the My Little Pony site:
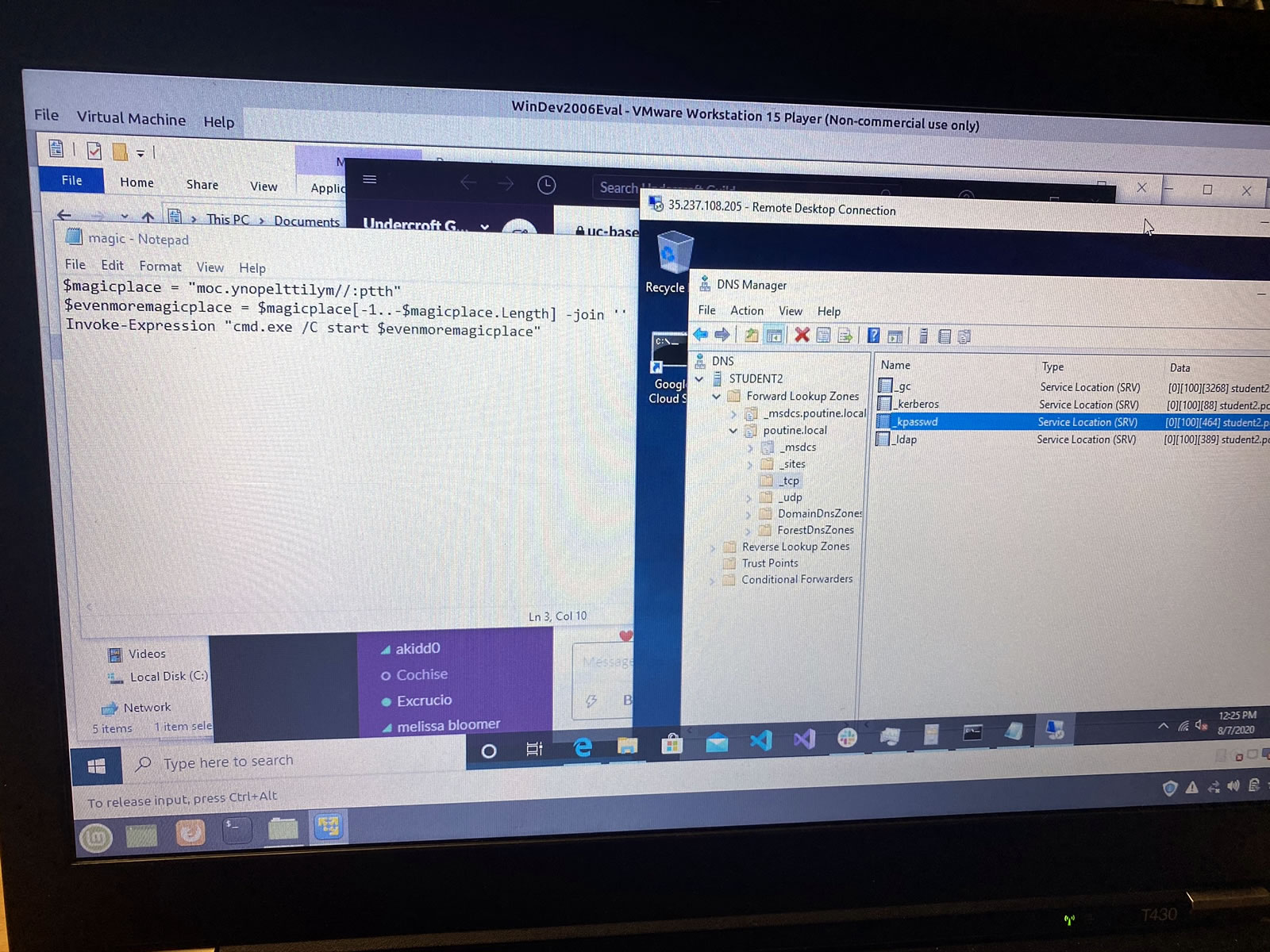
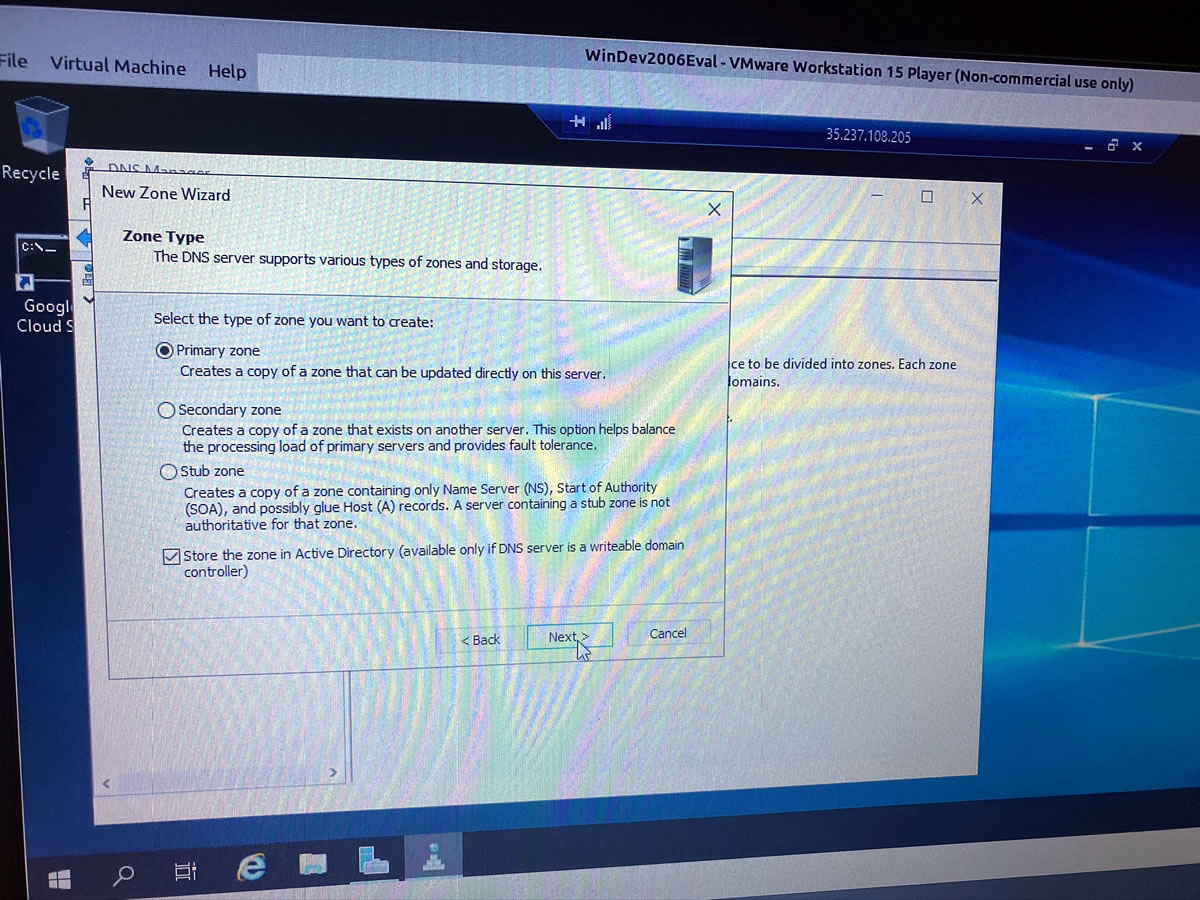
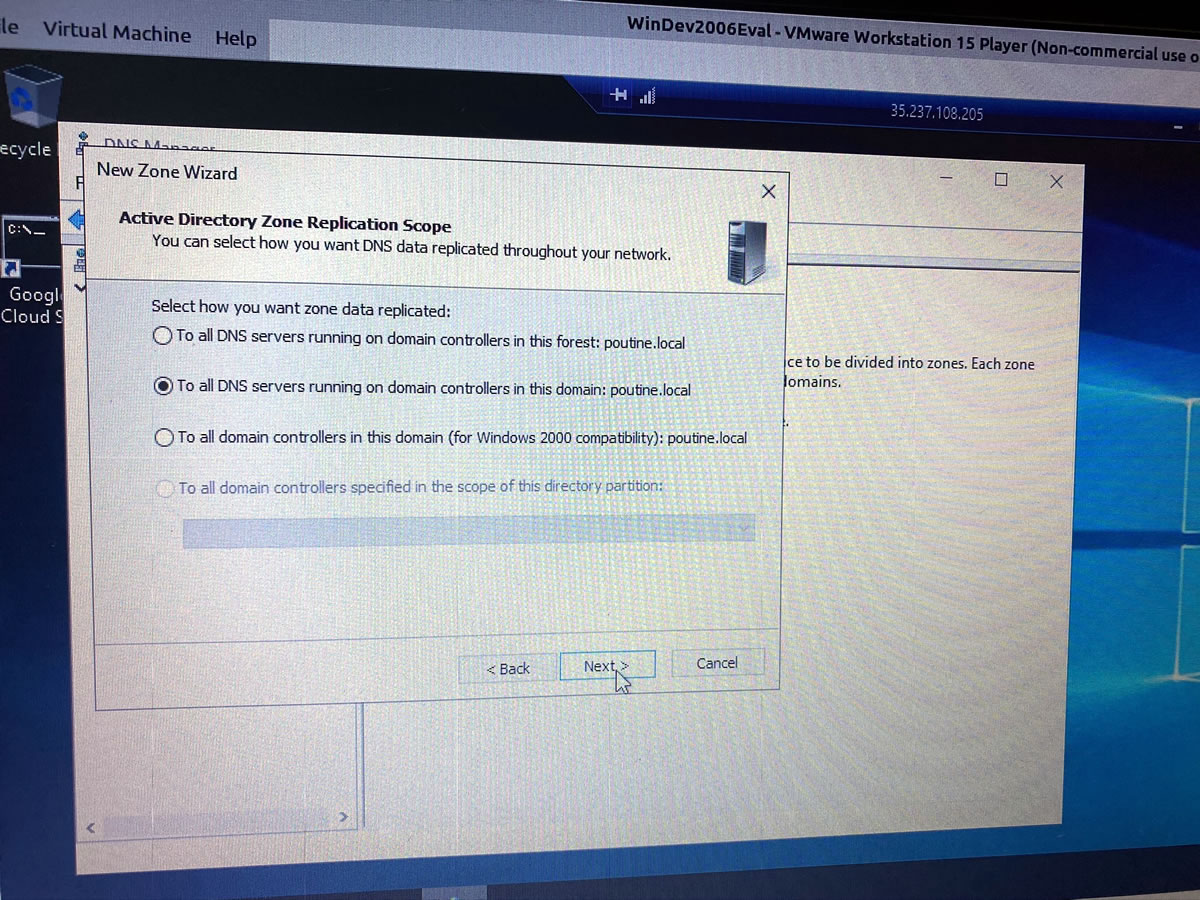
I can’t be as creative when setting up DNS…
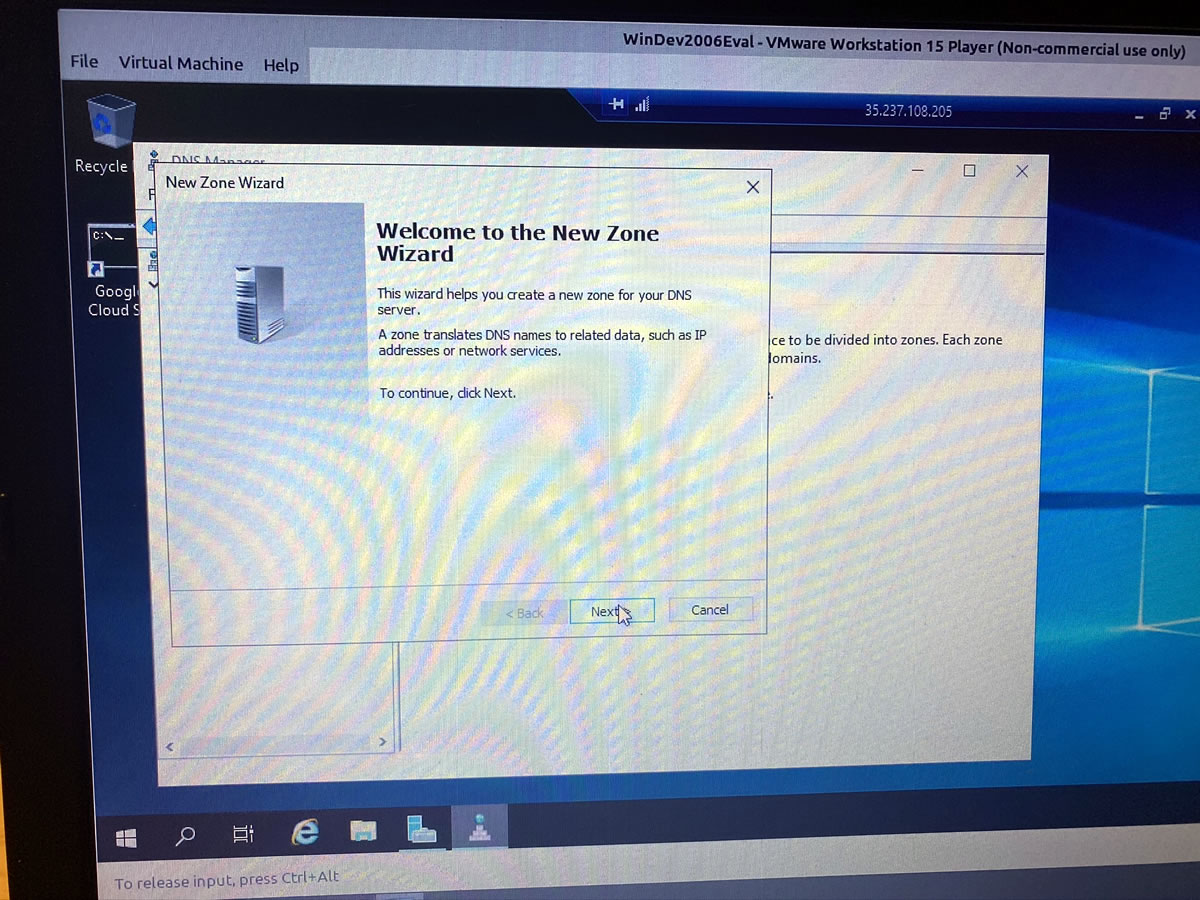
…but I can at least get it up and running:
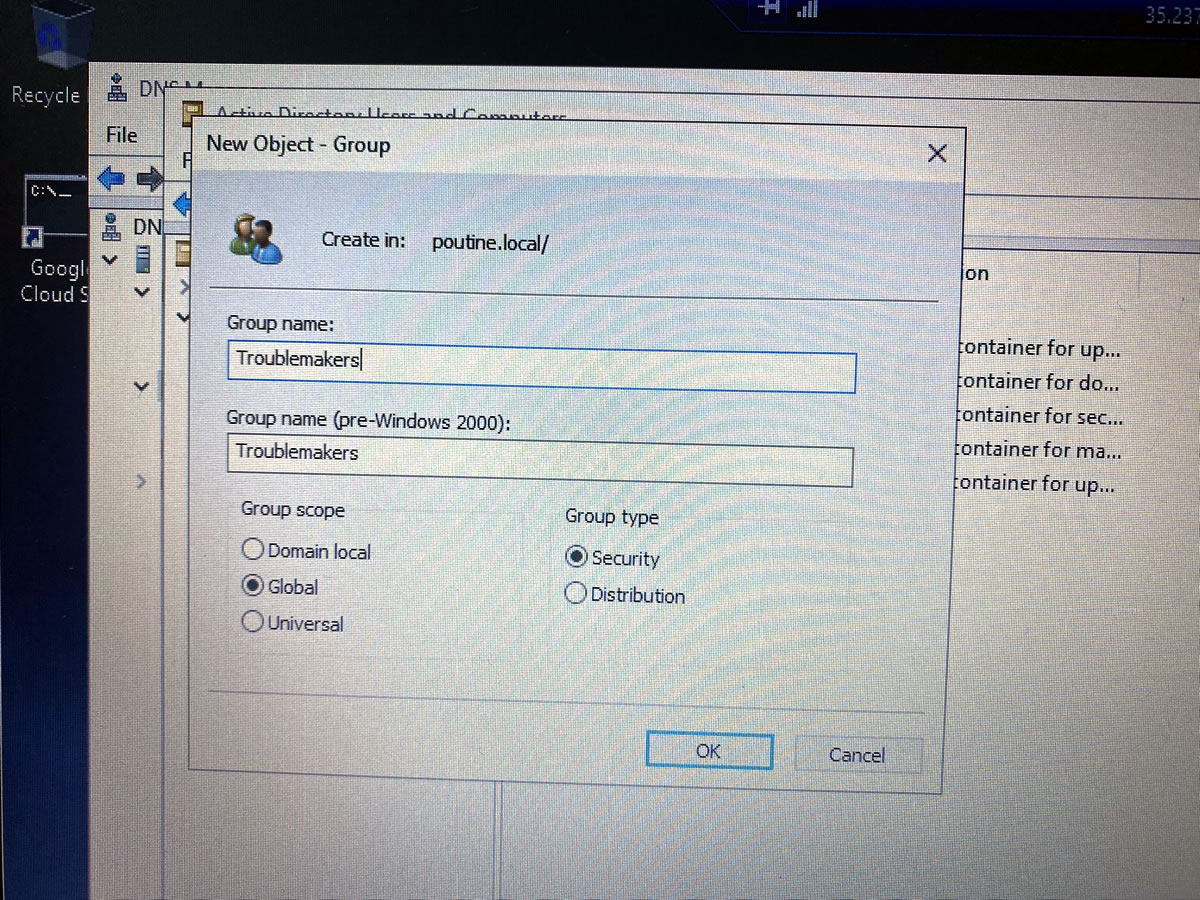
A good sysadmin has their users corralled into the appropriate groups:

On Monday, Week 4 — Information Security — begins. They promise that it’ll be the most intensive part of the course; in fact, they’ve added an extra hour to each day, which means the classes run from 8 to 5 instead of 8 to 4.

This should make Monday and Wednesday interesting, as I’m teaching the final 2 days of a Python course between 6 and 10 p.m. on those evenings.