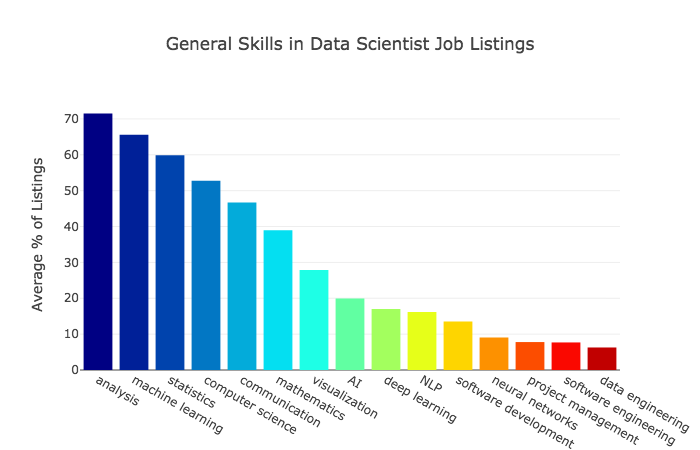
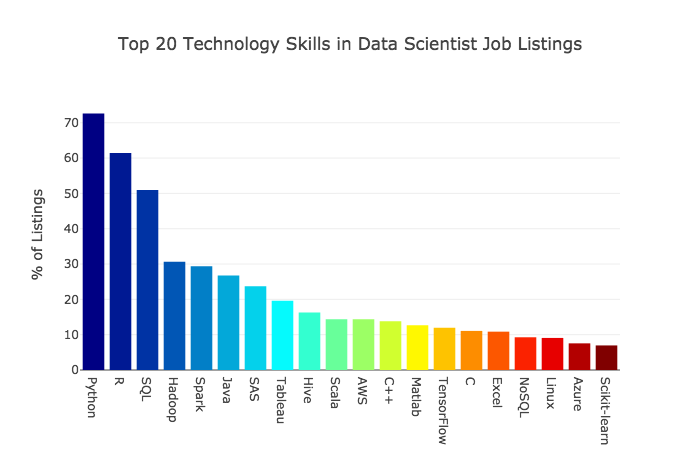
I remember the hype that surrounded the web in the late 1990s. I also remember the copious amount of well-intentioned misinformation that made the rounds as writers attempted to capitalize on that hype. It’s now data science’s turn, if this bit of “advertorial” in Harvard Business Review — Prioritize Which Data Skills Your Company Needs with This 2×2 Matrix — is any indication.
Written by Chris Littlewood, chief innovation and product officer of filtered.com (I’m not going to help them by linking to their site), a company that purports to use AI to “lift productivity by making learning recommendations”, the article clearly highlight’s the author’s ignorance and HBR’s willingness to publish any article that has to do with data or data science. To the credit of the readers, a number of them registered with the site simply to be able to post comments pointing out how nonsensical the article was.
Treat this article as an object lesson in technology hype, as well a sign that data science skills are seen as valuable.
Forget that the article mentioned above said that mathematics and statistics aren’t useful data skills — you can’t do data science without them! You’ll need to understand these 5 concepts (in addition to others):
- Statistical features
- Probability distributions
- Dimensionality reduction
- Under- and oversampling
- Bayesian statistics
This article in Towards Data Science provides a brief overview.

One of the better data science podcasts out there is Kyle Polich’s Data Skeptic, which has been around since 2014 and has over 400 episodes. The podcast features short mini-episodes explaining high level concepts in data science, and longer interview segments with researchers and practitioners.
I’ve just started working my way through this podcast, and have used the example in episode 5, Bayesian Updating, to explain Bayes’ Theorem to people who avoiding studying probability and stats. Give it a listen, then check out the rest of the podcast episodes!

Here’s a Harvard Business Review article on data science that’s actually worth reading:
Intelligent people find new uses for data science every day. Still, despite the explosion of interest in the data collected by just about every sector of American business — from financial companies and health care firms to management consultancies and the government — many organizations continue to relegate data-science knowledge to a small number of employees.
That’s a mistake — and in the long run, it’s unsustainable. Think of it this way: Very few companies expect only professional writers to know how to write. So why ask only professional data scientists to understand and analyze data, at least at a basic level?

Another article from Towards Data Science:
One of the first tasks that I was given in my job as a Data Scientist involved Web Scraping. This was a completely alien concept to me at the time, gathering data from websites using code, but is one of the most logical and easily accessible sources of data. After a few attempts, web scraping has become second nature to me and one of the many skills that I use almost daily.
In this tutorial I will go through a simple example of how to scrape a website to gather data on the top 100 companies in 2018 from Fast Track. Automating this process with a web scraper avoids manual data gathering, saves time and also allows you to have all the data on the companies in one structured file.
 If you can carve out a little free time every day between now and November 21st, you’ve got the opportunity to take every data science and AI course offered by 365 Data Science for free — and really free, as in they won’t ask you to enter your credit card number.
If you can carve out a little free time every day between now and November 21st, you’ve got the opportunity to take every data science and AI course offered by 365 Data Science for free — and really free, as in they won’t ask you to enter your credit card number.